I am scraping data with python. I get a csv file and can split it into columns in excel later. But I am encountering an issue I have not been able to solve. Sometimes the scraped items have two statuses and sometimes just one. The second status is thus moving the other values in the columns to the right and as a result the dates are not all in the same column which would be useful to sort the rows.
Do you have any idea how to make the columns merge if there are two statuses for example or other solutions?
Maybe is is also an issue that I still need to separate the values into columns manually with excel.
Here is my code
#call packages
import random
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import pandas as pd
# define driver etc.
service_obj = Service("C:\\Users\\joerg\\PycharmProjects\\dynamic2\\chromedriver.exe")
browser = webdriver.Chrome(service=service_obj)
# create loop
initiative_list = []
for i in range(0, 2):
url = 'https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives_de?page=' str(i)
browser.get(url)
time.sleep(random.randint(5, 10))
initiative_item = browser.find_elements(By.CSS_SELECTOR, "initivative-item")
initiatives = [item.text for item in initiative_item]
initiative_list.extend(initiatives)
df = pd.DataFrame(initiative_list)
#create csv
print(df)
df.to_csv('Initiativen.csv')
df.columns = ['tosplit']
new_df = df['tosplit'].str.split('\n', expand=True)
print(new_df)
new_df.to_csv('Initiativennew.csv')
I tried to merge the columns if there are two statuses.
CodePudding user response:
make the columns merge if there are two statuses for example or other solutions
[If by "statuses" you mean the yellow labels ending in OPEN/UPCOMING/etc, then] it should be taken care of by the following parts of the getDetails_iiaRow (below the dividing line):
labels = cssSelect(iiaEl, 'div.field span.label')
and then
'labels': ', '.join([l.text.strip() for l in labels])
So, multiple labels will be separated by commas (or any other separator you apply .join to).

initiative_item = browser.find_elements(By.CSS_SELECTOR, "initivative-item") initiatives = [item.text for item in initiative_item]
Instead of doing it like this and then having to split and clean things, you should consider extracting each item in a more specific manner and have each "row" be represented as a dictionary (with the column-names as the keys, so nothing gets mis-aligned later). If you wrap it as a function:
def cssSelect(el, sel): return el.find_elements(By.CSS_SELECTOR, sel)
def getDetails_iiaRow(iiaEl):
title = cssSelect(iiaEl, 'div.search-result-title')
labels = cssSelect(iiaEl, 'div.field span.label')
iiarDets = {
'title': title[0].text.strip() if title else None,
'labels': ', '.join([l.text.strip() for l in labels])
}
cvSel = 'div[translate] div:last-child'
for c in cssSelect(iiaEl, f'div:has(>{cvSel})'):
colName = cssSelect(c, 'div[translate]')[0].text.strip()
iiarDets[colName] = cssSelect(c, cvSel)[0].text.strip()
link = iiaEl.get_attribute('href')
if link[:1] == '/':
link = f'https://ec.europa.eu/{link}'
iiarDets['link'] = iiaEl.get_attribute('href')
return iiarDets
then you can simply loop through the pages like:
initiative_list = []
for i in range(0, 2):
url = f'https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives_de?page={i}'
browser.get(url)
time.sleep(random.randint(5, 10))
initiative_list = [
getDetails_iiaRow(iia) for iia in
cssSelect(browser, 'initivative-item>article>a ')
]
and the since it's all cleaned already, you can directly save the data with
pd.DataFrame(initiative_list).to_csv('Initiativen.csv', index=False)
The output I got for the first 3 pages looks like:
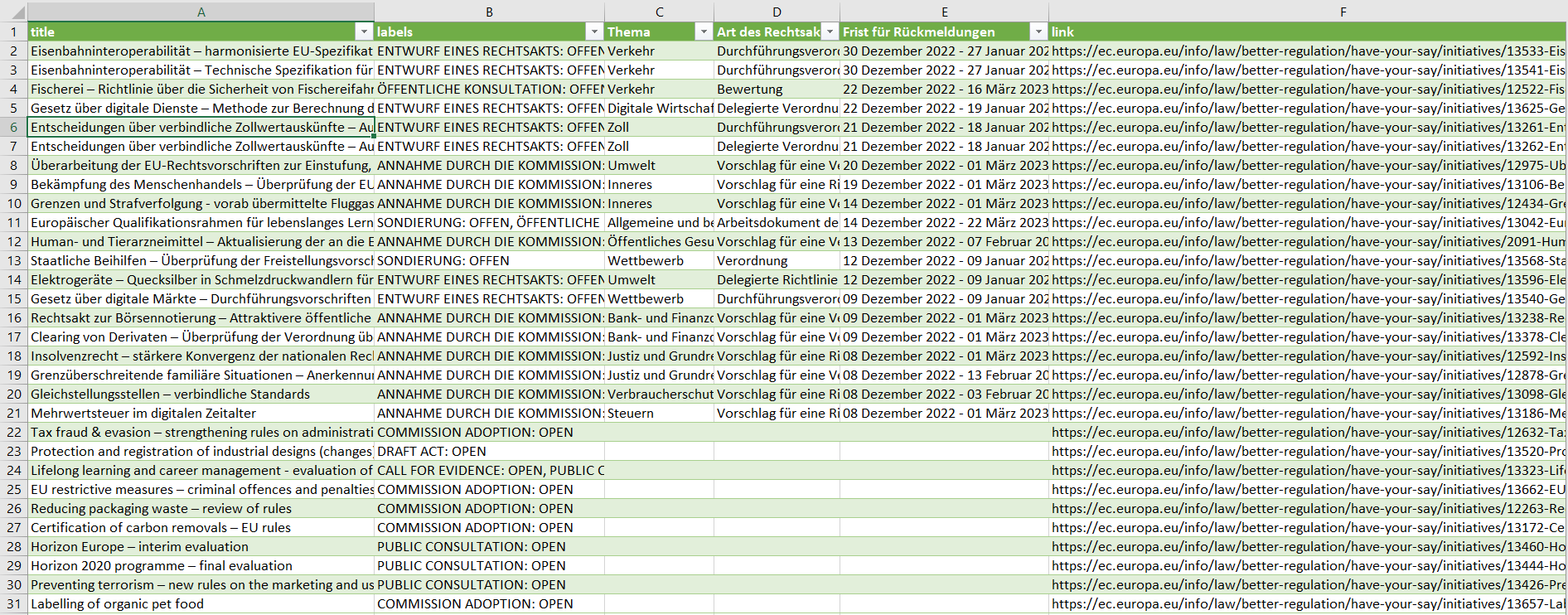
CodePudding user response:
I think it is worth working a little bit harder to get your data rationalised before putting it in the csv rather than trying to unpick the damage once ragged data has been exported.
A quick look at each record in the page suggests that there are five main items that you want to export and these correspond to the five top-level divs in the a element.
The complexity (as you note) comes because there are sometimes two statuses specified, and in that case there is sometimes a separate date range for each and sometimes a single date range.
I have therefore chosen to put the three ever present fields as the first three columns, followed next by the status date range columns as pairs. Finally I have removed the field names (these should effectively become the column headings) to leave only the variable data in the rows.
initiatives = [processDiv(item) for item in initiative_item]
def processDiv(item):
divs = item.find_elements(By.XPATH, "./article/a/div")
if "\n" in divs[0].text:
statuses = divs[0].text.split("\n")
if len(divs) > 5:
return [divs[1].text, divs[2].text.split("\n")[1], divs[3].text.split("\n")[1], statuses[0], divs[4].text.split("\n")[1], statuses[1], divs[5].text.split("\n")[1]]
else:
return [divs[1].text, divs[2].text.split("\n")[1], divs[3].text.split("\n")[1], statuses[0], divs[4].text.split("\n")[1], statuses[1], divs[4].text.split("\n")[1]]
else:
return [divs[1].text, divs[2].text.split("\n")[1], divs[3].text.split("\n")[1], divs[0].text, divs[4].text.split("\n")[1]]
The above approach sticks as close to yours as I can. You will clearly need to rework the pandas code to reflect the slightly altered data structure.
Personally, I would invest even more time in clearly identifying the best definitions for the fields that represent each piece of data that you wish to retrieve (rather than as simply divs 0-5), and extract the text directly from them (rather than messing around with split). In this way you are far more likely to create robust code that can be maintained over time (perhaps not your goal).