I have this: 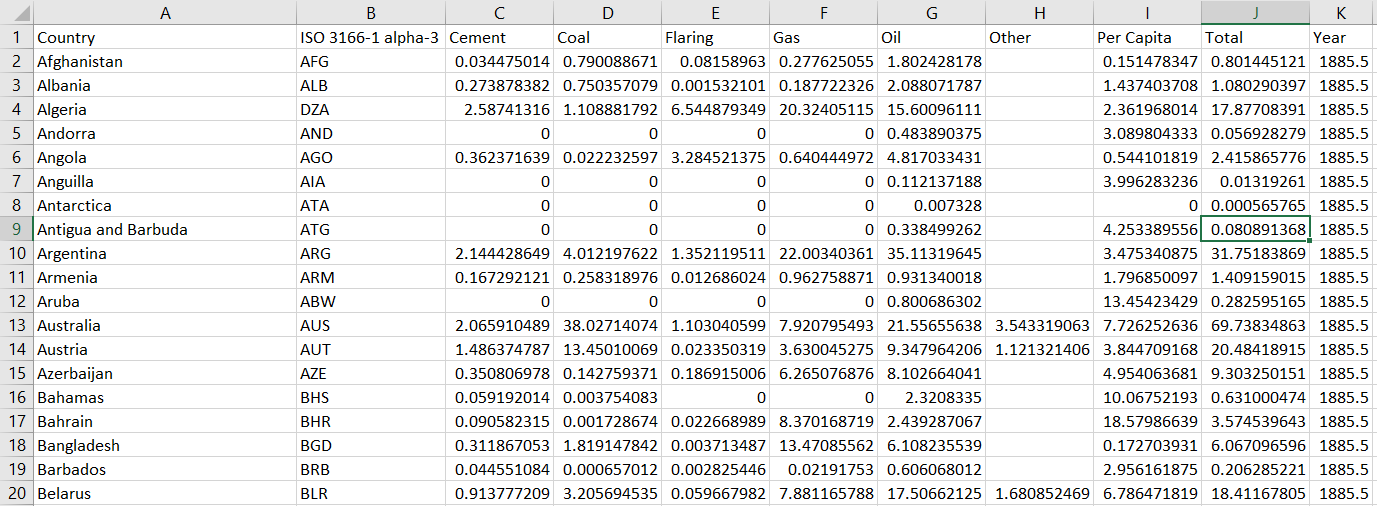
CodePudding user response:
You can use fillna after to compute mean:
import pandas as pd
df = pd.read_csv('GCB2022v27_MtCO2_flat.csv')
df = df.fillna(df1.groupby('Country')[df.columns[4:].transform('mean'))
Output:
>>> df
Country ISO 3166-1 alpha-3 Year Total Coal Oil Gas Cement Flaring Other Per Capita
0 Afghanistan AFG 1750 0.000000 0.790089 1.802428 0.277625 0.034475 0.081590 NaN 0.151478
1 Afghanistan AFG 1751 0.000000 0.790089 1.802428 0.277625 0.034475 0.081590 NaN 0.151478
2 Afghanistan AFG 1752 0.000000 0.790089 1.802428 0.277625 0.034475 0.081590 NaN 0.151478
3 Afghanistan AFG 1753 0.000000 0.790089 1.802428 0.277625 0.034475 0.081590 NaN 0.151478
4 Afghanistan AFG 1754 0.000000 0.790089 1.802428 0.277625 0.034475 0.081590 NaN 0.151478
... ... ... ... ... ... ... ... ... ... ... ...
63099 Global WLD 2017 36096.739276 14506.973805 12242.627935 7144.928128 1507.923185 391.992176 302.294047 4.749682
63100 Global WLD 2018 36826.506600 14746.830688 12266.016285 7529.846784 1569.218392 412.115746 302.478706 4.792753
63101 Global WLD 2019 37082.558969 14725.978025 12345.653374 7647.528220 1617.506786 439.253991 306.638573 4.775633
63102 Global WLD 2020 35264.085734 14174.564010 11191.808551 7556.290283 1637.537532 407.583673 296.301685 4.497423
63103 Global WLD 2021 37123.850352 14979.598083 11837.159116 7921.829472 1672.592372 416.525563 296.145746 4.693699
[63104 rows x 11 columns]
For remaining NaN values, you can chain another .fillna(0).
CodePudding user response:
If I understood well, for each country you want to replace the missing values of the columns ["Total", "Coal", "Oil", "Gas", "Cement", "Flaring", "Other"] by the country's average of those columns.
I would do something like this:
import numpy as np
metrics = ["Total", "Coal", "Oil", "Gas", "Cement", "Flaring", "Other"]
average_by_metrics = df.groupby("Country")[metrics].mean()
def fill_missing_values(row, col):
if np.isnan(row[col]):
return average_by_metric[row["Country"], col]
else:
return row[col]
for col in metrics :
df[col] = df.apply(lambda row: fill_missing_values(row, col), axis=1)