I would like to merge several sensor files which have a common column as "date" whose value is the time the sensor data was logged in. These sensors log the data every second. My task is to join these sensor data into one big dataframe. Since there could be a millisecond difference between the exact time the sensor data is logged in, we have created a window of 30 seconds using pandas pd.DatetimeIndex.floor method. Now I want to merge these files using the "date" column. The following is an example I was working on:
import pandas as pd
data1 = {
'date': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D'],
'value1': list(range(1, 20))
}
data2 = {
'date': ['A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D', 'D', 'D'],
'value2': list(range(1, 21))
}
It is not necessary that the different sensor files will have a same amount of data. The sensor data looks like the below. The vertical axis could relate to the time (increasing downward). The second (B) and second last window (C) should overlap as they belong to the same time window.
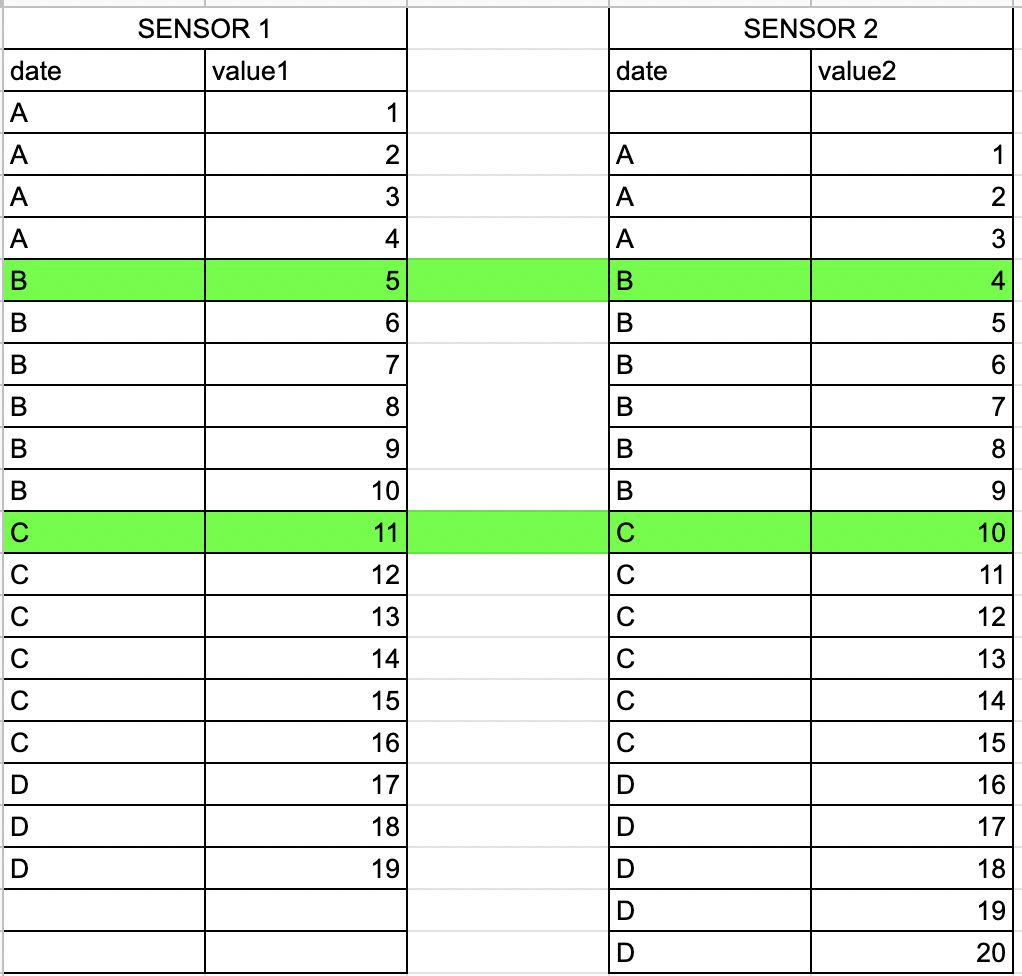
The resultant dataframe should look something like that:
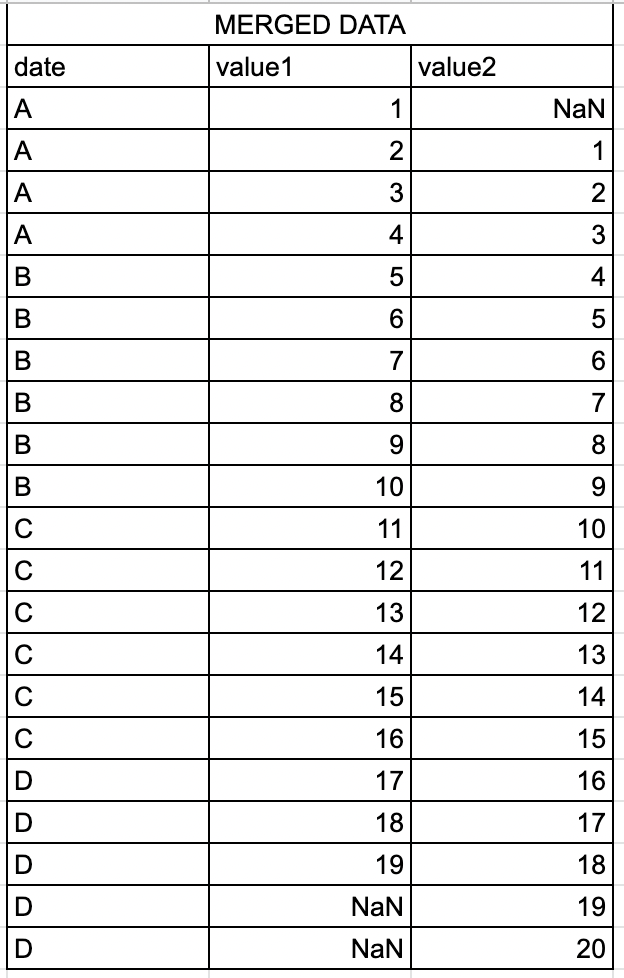
The A, B, C, and D values represent 30 sec window (for example, 'A' could be 07:00:00, 'B' could be 07:00:30, 'C' could be 07:01:00, and D could be 07:01:30). Now as we can see, the starting and ending window could be less than 30 (since sensor logs data every second, each window should have 30 values. In the example the number of rows of B and C window should be 30 each, not 6 as shown in the example). The reason is if the sensor has started reporting the values at 07:00:27, then it falls in the window of 'A' but could report only 3 values. Similarly, if the sensors has stopped reporting the values at 07:01:04, then it falls in the window of C but could report only 4 values. However, B and C windows will always have 30 values (In the example I have shown only 6 for ease of understanding). I would like to merge the dataframes such that the values from the same window overlap as shown in figure (B and C) while the start and end windows, should show NaN values where there is no data. (In the above example, Value1 from sensor1 started reporting data 1 second earlier while Value2 from sensor 2 stopped reporting data 2 seconds after sensor1 stopped reporting).
How to achieve such joins in the pandas?
CodePudding user response:
You can build your DataFrame with the following solution that requires only built-in Python structures. I don't see a particular interest in trying to use pandas methods. I'm not even sure that we can achieve this result only with pandas methods because you handle each value column differently, but I'm curious if you find a way.
from collections import defaultdict
import pandas as pd
data1 = {
'date': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D'],
'value1': list(range(1, 20))
}
data2 = {
'date': ['A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D', 'D', 'D'],
'value2': list(range(1, 21))
}
# Part 1
datas = [data1, data2]
## Compute where to fill dicts with NaNs
dates = sorted(set(data1["date"] data2["date"]))
dds = [{} for i in range(2)]
for d in dates:
for i in range(2):
dds[i][d] = [v for k, v in zip(datas[i]["date"], datas[i]["value%i" % (i 1)]) if k == d]
## Fill dicts
nan = float("nan")
for d in dates:
n1, n2 = map(len, [dd[d] for dd in dds])
if n1 < n2:
dds[0][d] = (n2 - n1) * [nan]
elif n1 > n2:
dds[1][d] = (n1 - n2) * [nan] dds[1][d]
# Part 2: Build the filled data columns
data = defaultdict(list)
for d in dates:
n = len(dds[0][d])
data["date"] = d * n
for i in range(2):
data["value%i" % (i 1)] = dds[i][d]
data = pd.DataFrame(data)
CodePudding user response:
if I understand the question correctly, you're might be looking for something like this:
data1 = pandas.DataFrame({
'date': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D'],
'value1': list(range(1, 20))
})
data2 = pandas.DataFrame({
'date': ['A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'C', 'C', 'D', 'D', 'D', 'D', 'D'],
'value2': list(range(1, 21))
})
b = pandas.concat([data1, data2]).sort_values(by='date', ascending=True)