I need help for a project on my uni. I have to reproduce a scientific paper which makes a sentiment analysis using twitter data. My prof has given me the data, but the dataset is in .txt format and they are only tweet IDs. How can I work with them? I created a twitter Api, I just don't know what to do with only twitter IDs with my analysis. is there a way where I can extract whole twitter text from id, to do the cleaning of data and classification?
I opened twitter Api
CodePudding user response:
We are not here to do your homework for you. You should be able to fetch tweet information (including text) by querying using the twitter ID
CodePudding user response:
Using 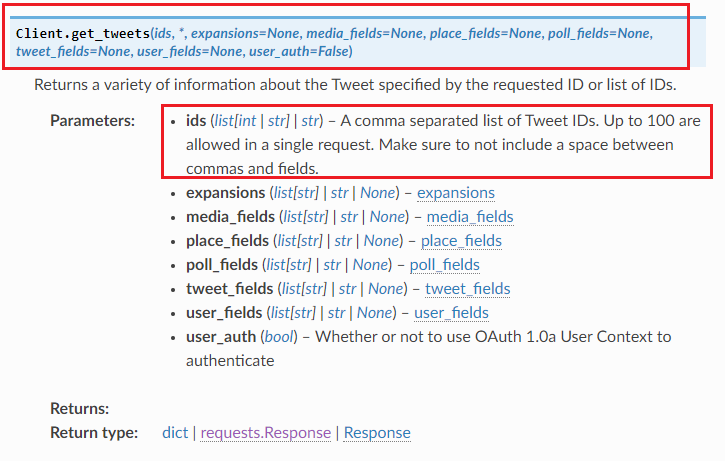
Demo code (suppose less then 100 ids)
import tweepy
bearer_token ="your token"
client = tweepy.Client(bearer_token=bearer_token)
tweets_file = open("tweet_ids.txt", "r")
data = tweets_file.read()
tweet_ids = data.split("\n")
tweets_file.close()
tweets = client.get_tweets(ids=tweet_ids)
for tweet in tweets.data:
print(tweet.id, " -> ",tweet.text)
print('---------------------------------------------------------')
With text file, the tweet_ids.txt file name.
1615009611186069504
1591179284991070208
1590380720853114881
result
>python get-tweets.py
1615009611186069504 -> Municipio: Santo Antônio Da Platina - PR
Setor censitário: 412410305000028
População: 718
Área (Km2): 1.31
Densidade (hab/Km2): 548.06
Zona: urbana