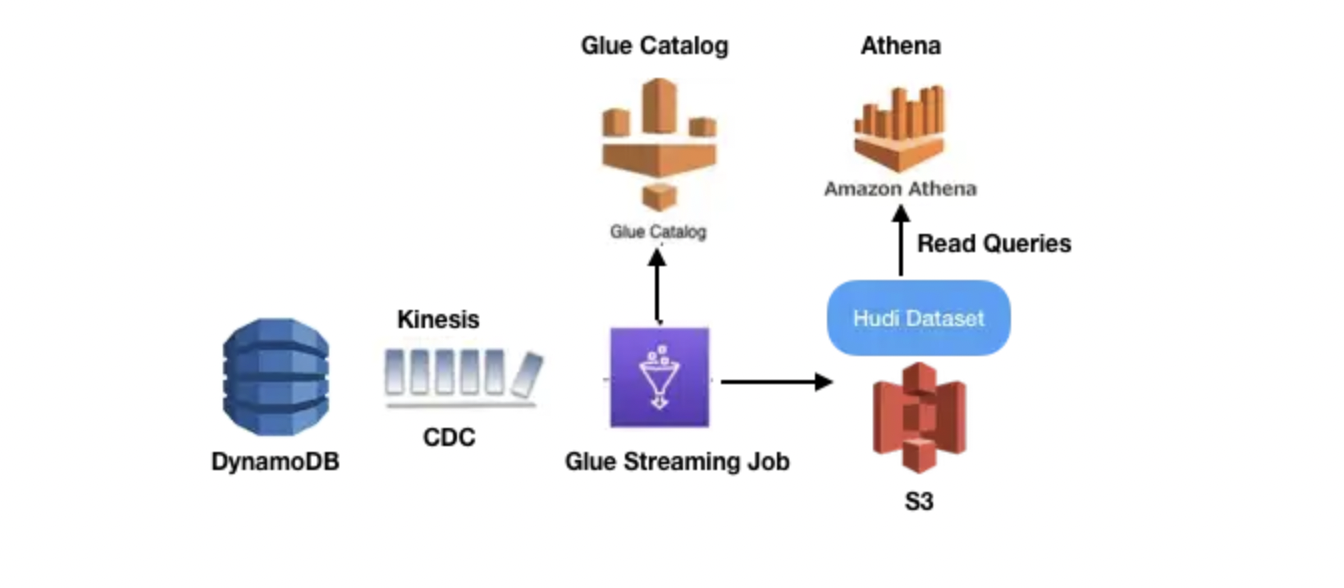
I currently have a DynamoDB stream configured which is inputing streams into Kinesis Data streams whenever insertion/updation happens and subsequently I have Glue tables which is taking input from above kinesis stream and then displaying the structural schema and also a Glue script is helping me create a Hudi Table which can be accessed using Athena. I'm currently able to monitor streaming data and able to see insertions/updations (simulating from boto3 using pycharm in my local machine) in my Athena table. Can we perform deletions aswell using the same Glue Job?
My Glue Script helping me create Glue Table (Hudi Table) looks as below -
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.session import SparkSession
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import DataFrame, Row
from pyspark.sql.functions import *
from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when
import datetime
from awsglue import DynamicFrame
import boto3
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ["JOB_NAME", "database_name", "kinesis_table_name", "starting_position_of_kinesis_iterator", "hudi_table_name", "window_size", "s3_path_hudi", "s3_path_spark" ])
spark = SparkSession.builder.config('spark.serializer','org.apache.spark.serializer.KryoSerializer').config('spark.sql.hive.convertMetastoreParquet','false').getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
database_name = args["database_name"]
kinesis_table_name = args["kinesis_table_name"]
hudi_table_name = args["hudi_table_name"]
s3_path_hudi = args["s3_path_hudi"]
s3_path_spark = args["s3_path_spark"]
commonConfig = {'hoodie.datasource.write.hive_style_partitioning' : 'true','className' : 'org.apache.hudi', 'hoodie.datasource.hive_sync.use_jdbc':'false', 'hoodie.datasource.write.precombine.field': 'id', 'hoodie.datasource.write.recordkey.field': 'id', 'hoodie.table.name': hudi_table_name, 'hoodie.consistency.check.enabled': 'true', 'hoodie.datasource.hive_sync.database': database_name, 'hoodie.datasource.hive_sync.table': hudi_table_name, 'hoodie.datasource.hive_sync.enable': 'true', 'path': s3_path_hudi}
partitionDataConfig = { 'hoodie.datasource.write.keygenerator.class' : 'org.apache.hudi.keygen.ComplexKeyGenerator', 'hoodie.datasource.write.partitionpath.field': "partitionkey, partitionkey2 ", 'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.MultiPartKeysValueExtractor', 'hoodie.datasource.hive_sync.partition_fields': "partitionkey, partitionkey2"}
incrementalConfig = {'hoodie.upsert.shuffle.parallelism': 68, 'hoodie.datasource.write.operation': 'upsert', 'hoodie.cleaner.policy': 'KEEP_LATEST_COMMITS', 'hoodie.cleaner.commits.retained': 2}
combinedConf = {**commonConfig, **partitionDataConfig, **incrementalConfig}
glue_temp_storage = s3_path_hudi
data_frame_DataSource0 = glueContext.create_data_frame.from_catalog(database = database_name, table_name = kinesis_table_name, transformation_ctx = "DataSource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "true"})
def processBatch(data_frame, batchId):
if (data_frame.count() > 0):
DataSource0 = DynamicFrame.fromDF(data_frame, glueContext, "from_data_frame")
your_map = [
('eventName', 'string', 'eventName', 'string'),
('userIdentity', 'string', 'userIdentity', 'string'),
('eventSource', 'string', 'eventSource', 'string'),
('tableName', 'string', 'tableName', 'string'),
('recordFormat', 'string', 'recordFormat', 'string'),
('eventID', 'string', 'eventID', 'string'),
('dynamodb.ApproximateCreationDateTime', 'long', 'ApproximateCreationDateTime', 'long'),
('dynamodb.SizeBytes', 'long', 'SizeBytes', 'long'),
('dynamodb.NewImage.id.S', 'string', 'id', 'string'),
('dynamodb.NewImage.custName.S', 'string', 'custName', 'string'),
('dynamodb.NewImage.email.S', 'string', 'email', 'string'),
('dynamodb.NewImage.registrationDate.S', 'string', 'registrationDate', 'string'),
('awsRegion', 'string', 'awsRegion', 'string')
]
new_df = ApplyMapping.apply(frame = DataSource0, mappings=your_map, transformation_ctx = "applymapping1")
abc = new_df.toDF()
inputDf = abc.withColumn('update_ts_dms',to_timestamp(abc["registrationDate"])).withColumn('partitionkey',abc["id"].substr(-1,1)).withColumn('partitionkey2',abc["id"].substr(-2,1))
# glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(inputDf, glueContext, "inputDf"), connection_type = "marketplace.spark", connection_options = combinedConf)
glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(inputDf, glueContext, "inputDf"), connection_type = "custom.spark", connection_options = combinedConf)
glueContext.forEachBatch(frame = data_frame_DataSource0, batch_function = processBatch, options = {"windowSize": "10 seconds", "checkpointLocation": s3_path_spark})
job.commit()
How do I implement deletion / script to reflect deletion changes in my dynamodb table in the same script? Is it even possible?
EDIT:
Added below lines to script. Resulting in deletion of all rows and empty table in Athena.
deleteDataConfig = {'hoodie.datasource.write.operation': 'delete'}
combinedConf = {**commonConfig, **partitionDataConfig, **incrementalConfig, **deleteDataConfig}
EDIT: Trying to add something like this in script after referring documentation of hudi
deleteConfig = {'hoodie.datasource.write.operation': 'delete', 'hoodie.delete.shuffle.parallelism': '1'}
Resulting in
23/01/18 13:35:06 ERROR ProcessLauncher: Error from Python:Traceback (most recent call last):
File "/tmp/glue_job_script.py", line 79, in <module>
glueContext.forEachBatch(frame = data_frame_DataSource0, batch_function = processBatch, options = {"windowSize": "10 seconds", "checkpointLocation": s3_path_spark})
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 678, in forEachBatch
raise e
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 668, in forEachBatch
query.start().awaitTermination()
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/streaming.py", line 101, in awaitTermination
return self._jsq.awaitTermination()
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 117, in deco
raise converted from None
pyspark.sql.utils.StreamingQueryException: An exception was raised by the Python Proxy. Return Message: Traceback (most recent call last):
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 2442, in _call_proxy
return_value = getattr(self.pool[obj_id], method)(*params)
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 196, in call
raise e
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 193, in call
self.func(DataFrame(jdf, self.sql_ctx), batch_id)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 653, in batch_function_with_persist
batch_function(data_frame, batchId)
File "/tmp/glue_job_script.py", line 76, in processBatch
glueContext.write_dynamic_frame.from_options(frame = DynamicFrame.fromDF(inputDf, glueContext, "inputDf"), connection_type = "custom.spark", connection_options = combinedConf)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/dynamicframe.py", line 644, in from_options
format_options, transformation_ctx)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 334, in write_dynamic_frame_from_options
format, format_options, transformation_ctx)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 357, in write_from_options
return sink.write(frame_or_dfc)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/data_sink.py", line 39, in write
return self.writeFrame(dynamic_frame_or_dfc, info)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/data_sink.py", line 32, in writeFrame
return DynamicFrame(self._jsink.pyWriteDynamicFrame(dynamic_frame._jdf, callsite(), info), dynamic_frame.glue_ctx, dynamic_frame.name "_errors")
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 111, in deco
return f(*a, **kw)
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 328, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o318.pyWriteDynamicFrame.
: org.apache.hudi.exception.HoodieIOException: Deletes issued without any prior commits
at org.apache.hudi.client.AbstractHoodieWriteClient.setWriteSchemaForDeletes(AbstractHoodieWriteClient.java:1190)
at org.apache.hudi.client.SparkRDDWriteClient.getTableAndInitCtx(SparkRDDWriteClient.java:484)
at org.apache.hudi.client.SparkRDDWriteClient.getTableAndInitCtx(SparkRDDWriteClient.java:448)
at org.apache.hudi.client.SparkRDDWriteClient.delete(SparkRDDWriteClient.java:254)
at org.apache.hudi.DataSourceUtils.doDeleteOperation(DataSourceUtils.java:229)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:194)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:164)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:46)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:90)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:185)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:223)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:220)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:181)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:134)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:133)
at org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:989)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232)
at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:110)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:135)
at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:135)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:253)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:134)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:989)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:438)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:415)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:301)
at com.amazonaws.services.glue.marketplace.connector.SparkCustomDataSink.writeDynamicFrame(CustomDataSink.scala:45)
at com.amazonaws.services.glue.DataSink.pyWriteDynamicFrame(DataSink.scala:72)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:750)
Is this even the right way ? Kindly help
CodePudding user response:
Hudi can achieve deletes if the version is greater than 0.5.1
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath);
CodePudding user response:
Was able to solve it by adding delete configs!