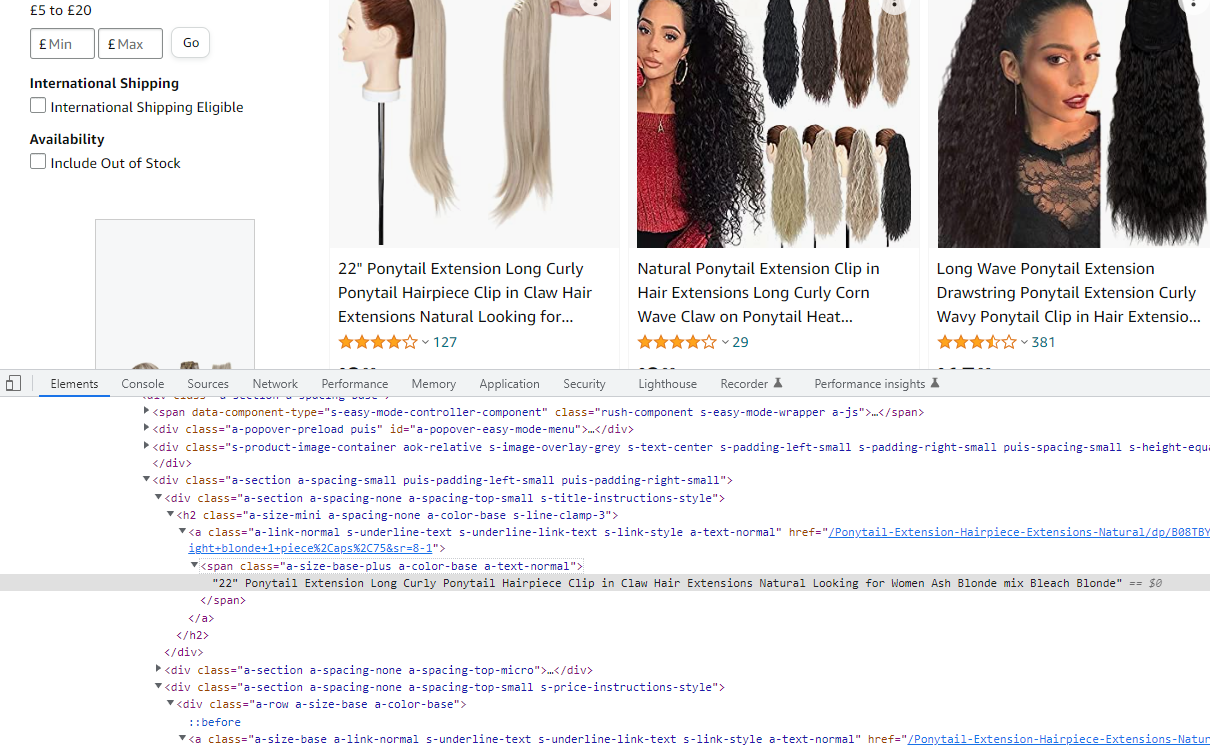
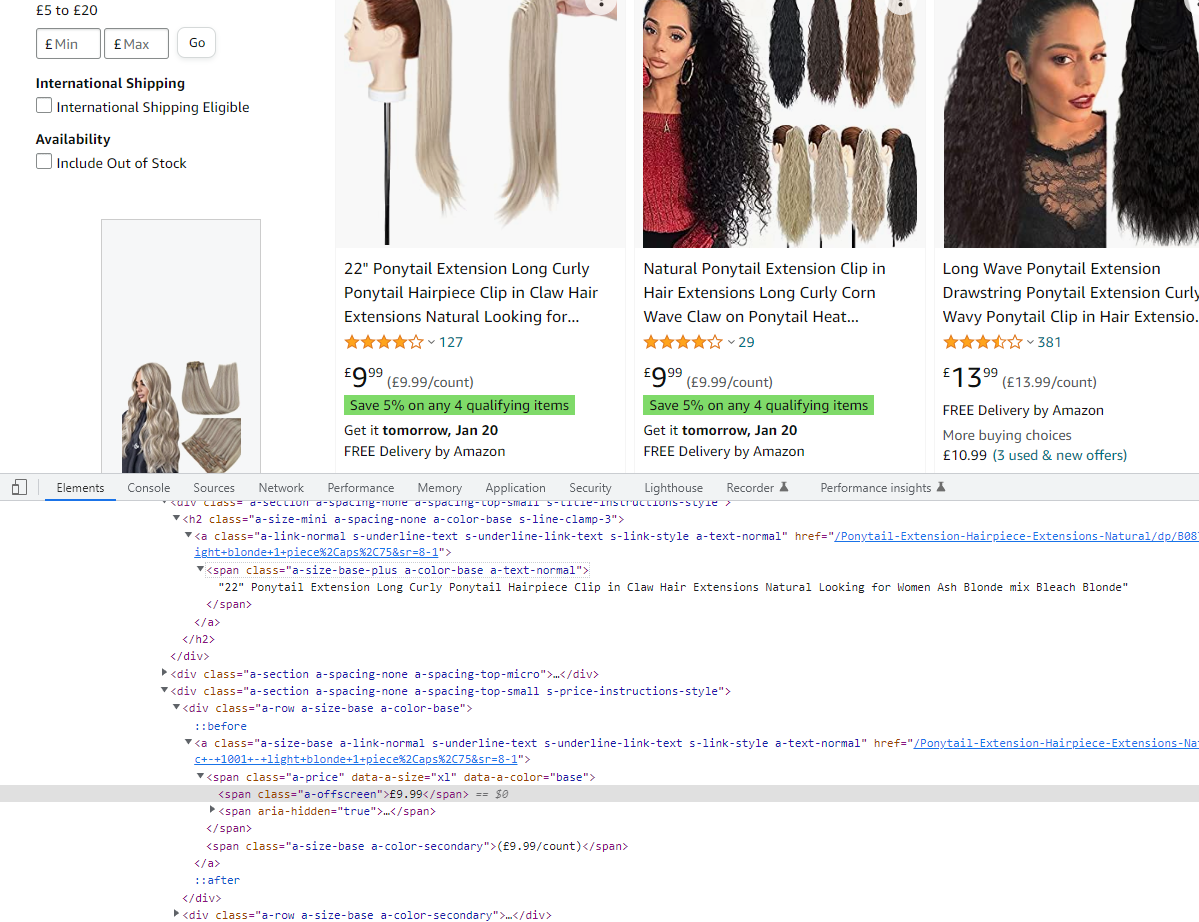
please can you help with this? I dont understand why I am getting an error. I am trying to get the description and price of the first 5 search results on the following web page. The code works for the csv file search and opening the browser, searching for the term and the browser displaying the search results it seems to fail when it tries to exectute the "title_element = driver.find_element(By.XPATH" line. I included the Xpaths that I copied from the elements on the inspect page in the code comments:
CodePudding user response:
You are having several problems here.
- XPath ending with
/text()is not a valid XPath to locate web element with Selenium. - Very long absolute XPaths like this
//*[@id='search']/div[1]/div[1]/div/span[1]/div[1]/div[3]/div/div/div/div/div[3]/div[3]/div[1]/a/span[1]/span[1]are extremelly breakable. - You are using the same XPath without any index in a loop. Even if these XPaths were correct you would get the same value each time.
- In order to extract a text value from web element
.textmethod should be applied on the web element.
To get the title and the price as you want try this:
for i in range(1, 6):
title_locator = "(//div[contains(@class,'s-title-instructions-style')]//span[@class='a-size-base-plus a-color-base a-text-normal'])[{}]".format(i)
price_locator = "(//div[contains(@class,'a-section')]//span[@class='a-price'])[{}]".format(i)
title = driver.find_element(By.XPATH, title_locator).text
price = driver.find_element(By.XPATH, price_locator).text