I already have the following plot, which I am already satisfied by
library(ggplot2)
library(wesanderson)
library(ggsignif)
library(ggdist)
dat1 <- as.data.frame(c(175.070, 279.760, 310.120, 454.370, 356.190, 398.720, 394.790, 427.940, 450.090, 452.240, 344.630, 374.450, 401.810,
366.250, 455.150, 455.150, 284.820, 325.640, 437.840, 455.150, 455.150, 454.900, 433.970, 346.830, 455.050, 455.150,
448.740, 455.150, 455.000, 455.150, 243.920, 295.660, 282.430, 305.190, 368.580, 348.440, 437.100, 453.180, 454.100,
44.464, 420.280, 455.150, 427.250, 101.490, 454.100, 454.810, 323.690, 454.410, 235.160, 294.870, 455.150, 330.460,
289.610, 236.310, 454.810, 299.020, 29.289, 39.988, 348.340, 455.150, 439.540, 409.910, 440.310, 433.090, 455.150,
198.890, 454.100, 346.370, 261.780, 280.760, 427.180, 455.150, 233.740, 334.040, 452.240, 411.890, 378.310, 354.410,
347.670, 439.970))
colnames(dat1) = "value"
dat1$group <- rep(NA,nrow(dat1))
for (i in 1:nrow(dat1)){
if (i <= 40){
dat1[i,]$group <- print('C')
}else{
dat1[i,]$group <- print('I')
}
}
dat1$group <- factor(dat1$group, levels = c('C','I'))
pltt <- rev(wes_palette(n=2, name="Darjeeling1"))
#Model 1
#M1 Loglikelihood
p1 <- ggplot(dat1, aes(x=group, y=value, color=group, fill=group))
scale_fill_manual(values=pltt, guide = "none")
scale_color_manual(values=pltt, guide = "none")
stat_halfeye(adjust = .33, width = .6, alpha=0.3, position = position_nudge(x=0.3))
geom_jitter(shape=16, position=position_jitter(0.1), alpha=0.5)
geom_signif(comparisons = list(c("C", "I")), tip_length = -0.01, y_position = -0.5,
map_signif_level=TRUE, test="wilcox.test", color = "black")
geom_boxplot(position = position_nudge(x=0.2), width=0.05,outlier.shape = NA, fill=alpha(0.2))
ylim(0,460)
theme(legend.position = "none",
axis.text=element_text(size=10),
axis.title=element_text(size=12),
plot.title = element_text(hjust = 0.5,size=14,face="bold"))
theme_light()
ggtitle("Data distribution")
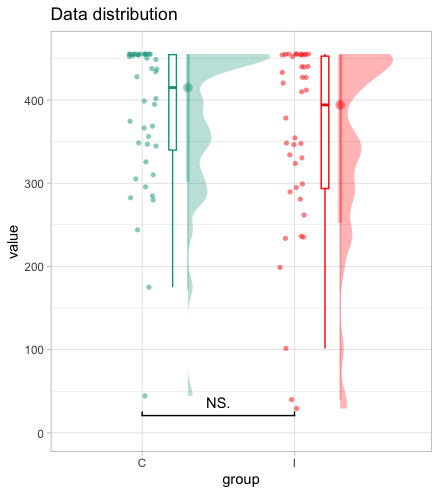
Now I was wondering whether there is a way to invert the order or mirror this composition into something like this.
I have read this post and I see there is a way of doing it with density plots, but I was wondering if anyone knows a way of doing it in composites of plots like mine.
Thanks in advance!
CodePudding user response:
An option could be by using each geom with a subset of your group. To get the stat_halfeye on the right side you could use the argument side for both. Here is a reproducible example:
library(ggplot2)
library(wesanderson)
library(ggsignif)
library(ggdist)
ggplot()
stat_halfeye(data = subset(dat1, group == "C"),
aes(x=group, y=value, color=group, fill=group),
adjust = .33, width = .6, alpha=0.3, position = position_nudge(x=-0.3), side = "left")
geom_jitter(data = subset(dat1, group == "C"),
aes(x=group, y=value, color=group, fill=group),
shape=16, position=position_jitter(0.1), alpha=0.5)
geom_boxplot(data = subset(dat1, group == "C"),
aes(x=group, y=value, color=group, fill=group),
position = position_nudge(x=-0.2), width=0.05,outlier.shape = NA, fill=alpha(0.2))
stat_halfeye(data = subset(dat1, group == "I"),
aes(x=group, y=value, color=group, fill=group),
adjust = .33, width = .6, alpha=0.3, position = position_nudge(x=0.3), side = "right")
geom_jitter(data = subset(dat1, group == "I"),
aes(x=group, y=value, color=group, fill=group),
shape=16, position=position_jitter(0.1), alpha=0.5)
geom_boxplot(data = subset(dat1, group == "I"),
aes(x=group, y=value, color=group, fill=group),
position = position_nudge(x=0.2), width=0.05,outlier.shape = NA, fill=alpha(0.2))
geom_signif(data = dat1,
aes(x=group, y=value, color=group, fill=group),
comparisons = list(c("C", "I")), tip_length = -0.01, y_position = -0.5,
map_signif_level=TRUE, test="wilcox.test", color = "black")
ylim(0,460)
theme(legend.position = "none",
axis.text=element_text(size=10),
axis.title=element_text(size=12),
plot.title = element_text(hjust = 0.5,size=14,face="bold"))
theme_light()
ggtitle("Data distribution")
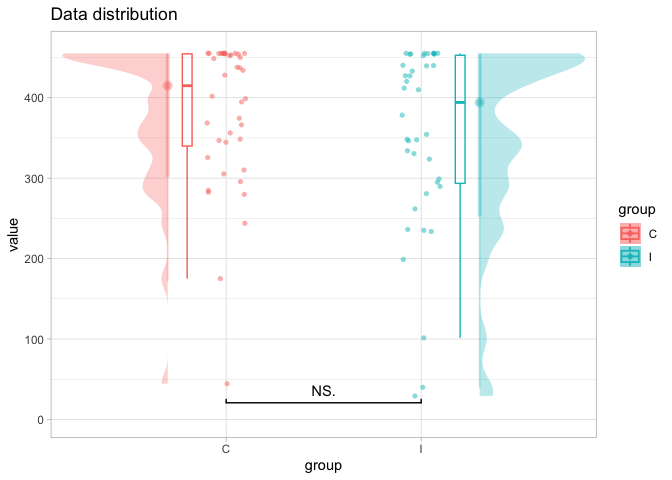
Created on 2023-01-19 with reprex v2.0.2