For a project, I'm trying to scrape the macronutrients from this 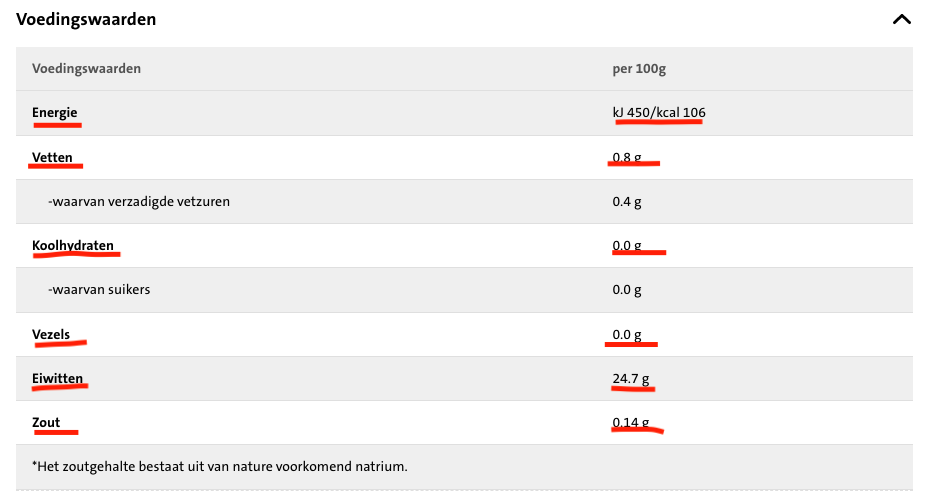 .
.
CodePudding user response:
Just in addition to @Jurakin how decomposes elements from the tree, you could also select only elements you need with css selectors, so tree will not be effected in that way. stripped_strings will extract the pairs texts you can build your DataFrame on.
EDIT
As you only like to scrape the red marked parts, you could go with the same methode, but have to use pandas.set_index(0) and pandas.T to transform and make the first column to headers.
Example
import requests
import pandas as pd
soup = BeautifulSoup(requests.get('https://www.jumbo.com/producten/jumbo-scharrelkip-filet-800g-515026BAK',headers = {'User-Agent': 'Mozilla/5.0'}, cookies={'CONSENT':'YES '}).text)
pd.DataFrame(
(e.stripped_strings for e in soup.select('table tr:not(:has(th,td.sub-label,td[colspan]))')),
).set_index(0).T
Output
| Energie | Vetten | Koolhydraten | Vezels | Eiwitten | Zout | |
|---|---|---|---|---|---|---|
| 1 | kJ 450/kcal 106 | 0.8 g | 0.0 g | 0.0 g | 24.7 g | 0.14 g |
Example
import requests
import pandas as pd
soup = BeautifulSoup(requests.get('https://www.jumbo.com/producten/jumbo-scharrelkip-filet-800g-515026BAK',headers = {'User-Agent': 'Mozilla/5.0'}, cookies={'CONSENT':'YES '}).text)
pd.DataFrame(
(e.stripped_strings for e in soup.select('table tr:not(:has(th,td.sub-label,td[colspan]))')),
columns = soup.select_one('table tr').stripped_strings
)
Output
| Voedingswaarden | per 100g | |
|---|---|---|
| 0 | Energie | kJ 450/kcal 106 |
| 1 | Vetten | 0.8 g |
| 2 | Koolhydraten | 0.0 g |
| 3 | Vezels | 0.0 g |
| 4 | Eiwitten | 24.7 g |
| 5 | Zout | 0.14 g |
CodePudding user response:
You can remove those tr that have a child td that has a sub-label class or contains a col-span attribute, then pass it to pd.read_html to create a data frame.
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://www.jumbo.com/producten/jumbo-scharrelkip-filet-800g-515026BAK"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5026.0 Safari/537.36 Edg/103.0.1254.0"
# get page source code
page = requests.get(url, headers={"user-agent": user_agent})
page.raise_for_status()
soup = BeautifulSoup(page.content, "html.parser")
# find table
table = soup.find("table")
# check existence of the table
assert table, "no table found"
print(table)
# select garbage
# - td containing sub-label in class
# - td with colspan attribute
garbage = table.find_all("td", class_="sub-label") \
table.find_all("td", colspan=True)
for item in garbage:
# remove item with its parent tr
item.parent.decompose()
# load html into dataframe
df = pd.read_html(str(table))[0]
print(df)
This is the table printed from code:
<table aria-label="Table containing info" data-v-038af5f8="" data-v-e2cf3b44="">
<thead data-v-038af5f8="" data-v-e2cf3b44="">
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<th data-v-038af5f8="" data-v-e2cf3b44="" id="Voedingswaarden"> Voedingswaarden </th>
<th data-v-038af5f8="" data-v-e2cf3b44="" id="per 100g"> per 100g </th>
</tr>
</thead>
<tbody data-v-038af5f8="" data-v-e2cf3b44="">
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Energie</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">kJ 450/kcal 106</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Vetten</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.8 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
# contains sub-label class
<td data-v-038af5f8="" data-v-e2cf3b44="">-waarvan verzadigde vetzuren</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.4 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Koolhydraten</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.0 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
# contains sub-label class
<td data-v-038af5f8="" data-v-e2cf3b44="">-waarvan suikers</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.0 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Vezels</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.0 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Eiwitten</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">24.7 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
<td data-v-038af5f8="" data-v-e2cf3b44="">Zout</td>
<td data-v-038af5f8="" data-v-e2cf3b44="">0.14 g</td>
</tr>
<tr data-v-038af5f8="" data-v-e2cf3b44="">
# contains colspan attribute
<td colspan="2" data-v-038af5f8="" data-v-e2cf3b44="">*Het zoutgehalte bestaat uit van nature voorkomend natrium.</td>
</tr>
</tbody>
</table>
Output dataframe:
Voedingswaarden per 100g
0 Energie kJ 450/kcal 106
1 Vetten 0.8 g
2 Koolhydraten 0.0 g
3 Vezels 0.0 g
4 Eiwitten 24.7 g
5 Zout 0.14 g