I am importing an HTML file. It has the data in a weird format and with multi index.
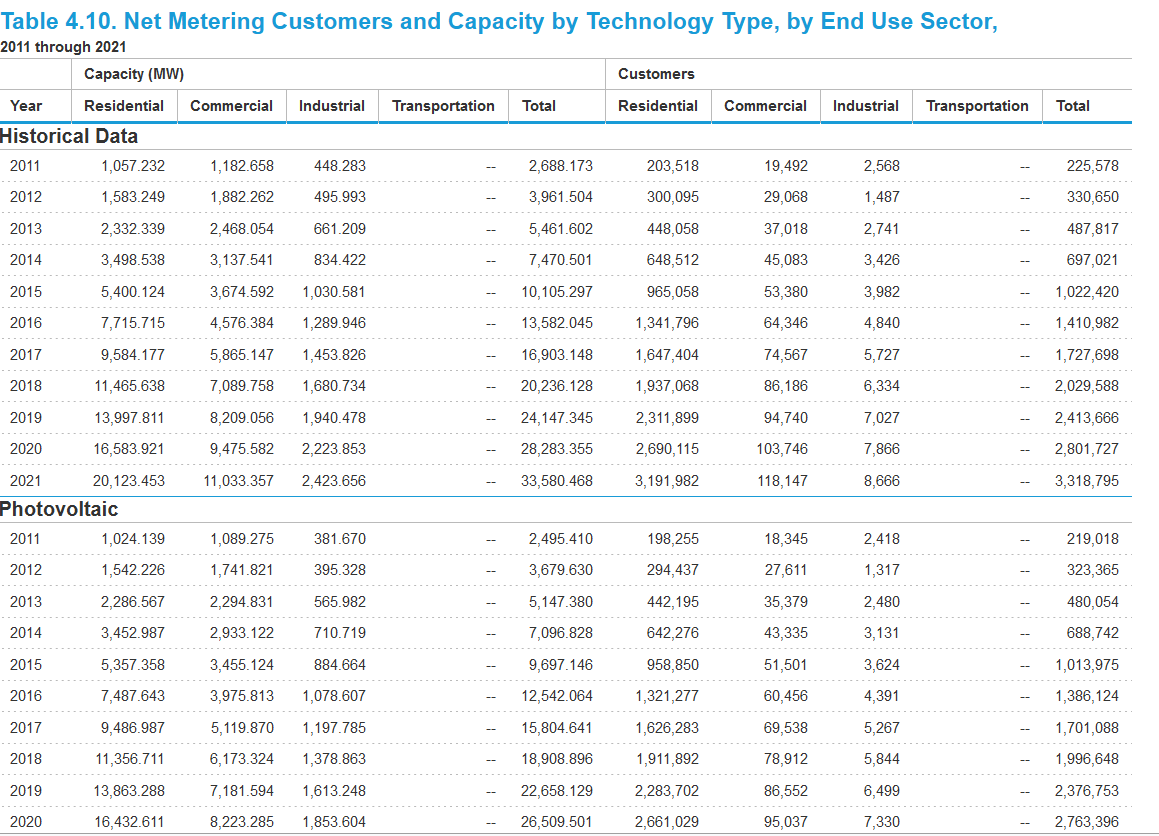
I am particularly interested in importing the table 'Photovoltaic' and it starts at line 10 in the big table. The table seems to be of multiindex.
code:
net_met_cus = 'https://www.eia.gov/electricity/annual/html/epa_04_10.html'
net_met = pd.read_html(net_met_cus)
print(len(net_met))
net_met_pv = net_met[1]
# Photovoltaic table starts at 12 row
print(net_met_pv.loc[12])
Unnamed: 0_level_0 Year Photovoltaic
Capacity (MW) Residential Photovoltaic
Commercial Photovoltaic
Industrial Photovoltaic
Transportation Photovoltaic
Total Photovoltaic
Customers Residential Photovoltaic
Commercial Photovoltaic
Industrial Photovoltaic
Transportation Photovoltaic
Total Photovoltaic
Name: 12, dtype: object
# Is it multiindex
print(net_met_pv.loc[12].index)
MultiIndex([('Unnamed: 0_level_0', 'Year'),
( 'Capacity (MW)', 'Residential'),
( 'Capacity (MW)', 'Commercial'),
( 'Capacity (MW)', 'Industrial'),
( 'Capacity (MW)', 'Transportation'),
( 'Capacity (MW)', 'Total'),
( 'Customers', 'Residential'),
( 'Customers', 'Commercial'),
( 'Customers', 'Industrial'),
( 'Customers', 'Transportation'),
( 'Customers', 'Total')],
)
# Okay, let's flaten it
net_met_pv.to_flat_index()
Present output:
AttributeError: 'DataFrame' object has no attribute 'to_flat_index'
CodePudding user response:
.to_flat_index() is a method of Index or Multindex, so you should call using net_met_pv.loc[12].index.to_flat_index() or similar calls.
Ref: https://pandas.pydata.org/docs/reference/api/pandas.Index.to_flat_index.html?highlight=to_flat_index#pandas.Index.to_flat_index https://pandas.pydata.org/docs/reference/api/pandas.MultiIndex.to_flat_index.html?highlight=to_flat_index#pandas.MultiIndex.to_flat_index