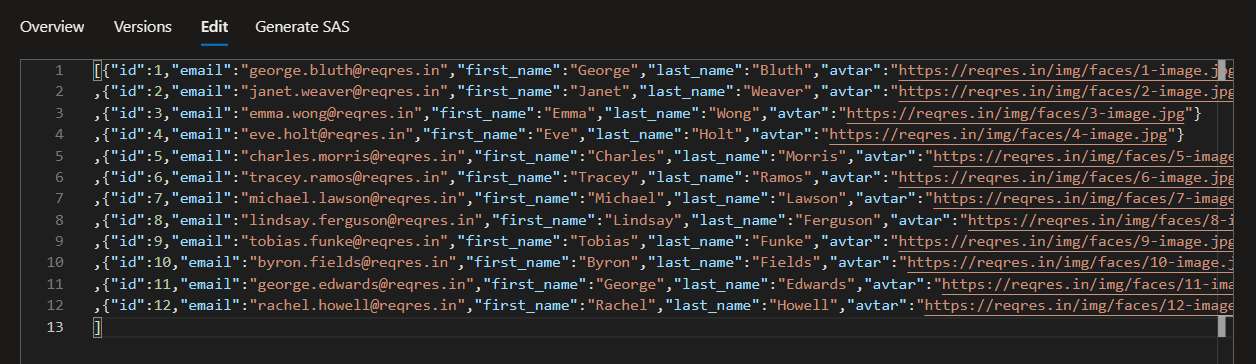
I'm building a pipeline, which copy a response from a API into a file in my storage account. There is also an element of pagination. However, that works like a charm and i get all my data from all the pages.
My result is something like this:
{"data": {
"id": "Something",
"value": "Some other thing"
}}
The problem, is that the copy function just appends the response to the file and thereby making it invalid JSON, which is a big problem further down the line. The final output would look like:
{"data": {
"id": "22222",
"value": "Some other thing"
}}
{"data": {
"id": "33333",
"value": "Some other thing"
}}
I have tried everything I could think of and google my way to, but nothing changes how the data is appended to the file and i'm stuck with an invalid JSON file :(
As a backup plan, i'll just make a loop and create a JSON file for each PAGE. But that seems a bit janky and really slow
Anyone got an idea or have a solution for my problem?
CodePudding user response:
When you copy data from Rest API to blob storage it will copy data in the form of set of objects by default.
Example:
sample data
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604"}
sink data
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691"}
This is the invalid format of Json.
To work around this, select file pattern in sink activity setting as Array of objects this will return array of all objects.
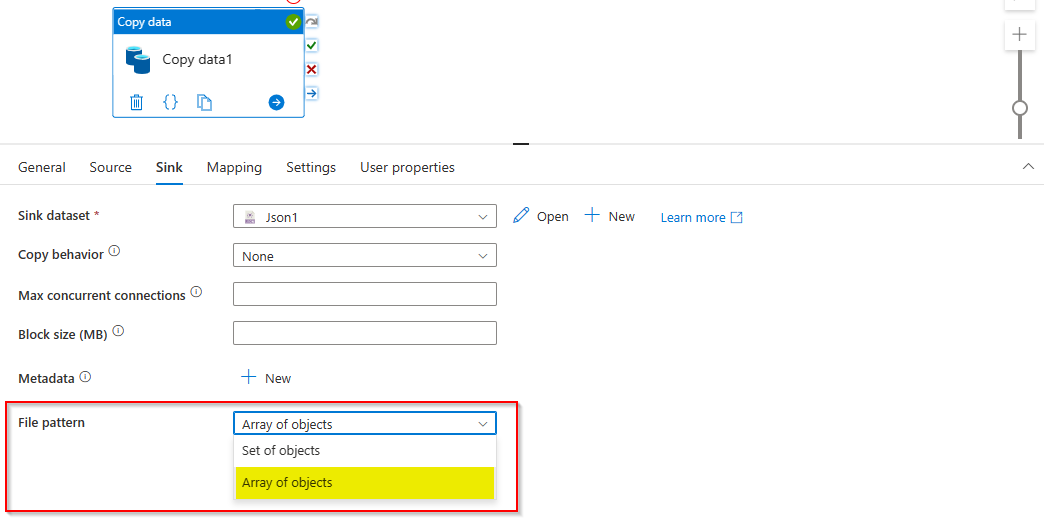
Output: