I have a CSV sheet with two rows of data in rows 4 and 5. Row 4 has the titles and row 5 has the corresponding data for it. How do I pull data and put it in another CSV sheet? The title row has formatting similar to
Title_XYZ[0].XXX_YYY_Record.XXX_YYY.AAA
Title_XYZ[0].XXX_YYY_Record.XXX_YYY.BBB
Title_XYZ[1].XXX_YYY_Record.XXX_YYY.AAA
Title_XYZ[1].XXX_YYY_Record.XXX_YYY.BBB
Title_XYZ[2].XXX_YYY_Record.XXX_YYY.AAA
Title_XYZ[2].XXX_YYY_Record.XXX_YYY.BBB
with the number in the [] changing with every new cell? I can't use pandas.
I have tried reading the files using import CSV, pulling the file to read, and using
header = lines[4].split(',')
to grab data and write a new CSV file using that but that just copies and paste the data instead of assigning AAA with AAA and BBB with BBB.
The data looks something like this:
| Title_XYZ[0].XXX_YYY_Record.XXX_YYY.AAA | Title_XYZ[0].XXX_YYY_Record.XXX_YYY.BBB | Title_XYZ[1].XXX_YYY_Record.XXX_YYY.AAA | Title_XYZ[1].XXX_YYY_Record.XXX_YYY.BBB |
|---|---|---|---|
| 12 | 13 | 14 | 15 |
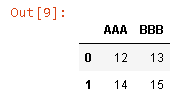
And the output should look like
| AAA | BBB |
|---|---|
| 12 | 13 |
| 14 | 15 |
CodePudding user response:
import pandas as pd
import re
data="""
Title_XYZ[0].XXX_YYY_Record.XXX_YYY.AAA Title_XYZ[0].XXX_YYY_Record.XXX_YYY.BBB Title_XYZ[1].XXX_YYY_Record.XXX_YYY.AAA Title_XYZ[1].XXX_YYY_Record.XXX_YYY.BBB
12 13 14 15
"""
records = []
regex = r"(?:(?P<AAA>\d )\s(?P<BBB>\d )){1,2}"
for match in re.finditer(regex, data):
records.append(match.groupdict())
pd.DataFrame(records)