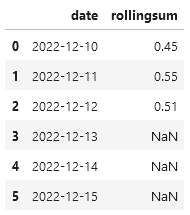
I have two dataframes with same index and column names.
In one dataframe I have time series of equity prices. In the other one I have the rolling sum of these equity returns.
The problem that I have now is that in the dataframe with the rolling sum there are still values even when there are no equity prices at that time.
So if the equity left the portfolio on January the 2nd for example, I will have ongoing rolling sums for 10 more days, if 10 was my period value.
I want to clear those 10 more fields in the rolling sum dataframe. So that the rolling sum time series stops at the date similar to the time series of the equity prices.
These are two columns
| Index | Stock A |
|---|---|
| 2022-12-10 | 23 |
| 2022-12-11 | 25 |
| 2022-12-12 | 21 |
| 2022-12-13 | |
| 2022-12-14 | |
| 2022-12-15 |
| Index | Rolling sum |
|---|---|
| 2022-12-10 | 0,54 |
| 2022-12-11 | 0,55 |
| 2022-12-12 | 0,51 |
| 2022-12-13 | 0,49 |
| 2022-12-14 | 0,48 |
| 2022-12-15 | 0,47 |
this is how it should look like
| Index | Rolling sum |
|---|---|
| 2022-12-10 | 0,54 |
| 2022-12-11 | 0,55 |
| 2022-12-12 | 0,51 |
| 2022-12-13 | |
| 2022-12-14 | |
| 2022-12-15 |
let df be my equity dataframe. let df1 be my dataframe with the rolling sums.
I tried to replace the empty fields in df with fillna(0) and change the dataframe to a bool. Then replace all 0 fields with False. Then compare to df2 but the fields in df2 didn't change.
df = df .fillna(0)
df_bool = df.copy()
df_bool = df_bool.astype(bool)
df_bool .replace(False, pd.NA, inplace=False)
df2.where(df_bool , False).reset_index()
I don't know where I made an error or if there is a smarter solution. For sure there will be one. short said....if a field in df is empty it should also be empty in df2 without changing the other existing values in in df2.
Edit:This is just an example. I have a few hundred columns of stock data in the dataframes that have to be cleared that way. so i think the solution should consider the whole dataframe.
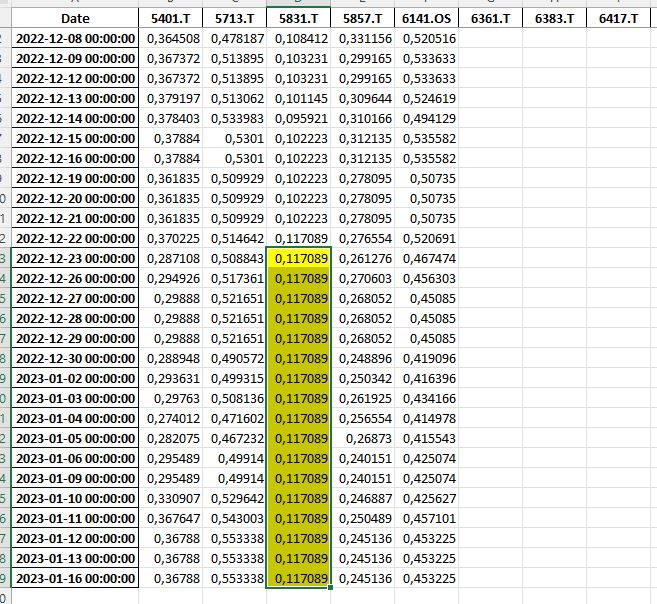
the picture in the link are the stock prices yello is the difference that should be empty in the rolling sum example
CodePudding user response:
You could use isin
empty_index = df_stock.loc[df_stock['Stock A'].isna(), 'Index']
df_rolling_sum.loc[df_rolling_sum['Index'].isin(empty_index), 'Rolling Sum'] = np.nan
CodePudding user response:
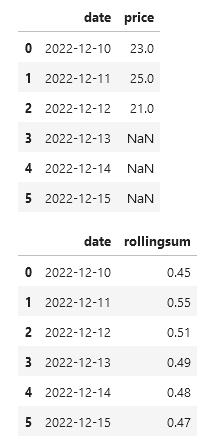
For future questions, try to provide sample data, as code, we can use to help you:
import pandas as pd
tableA = pd.DataFrame(dict(
date= ['2022-12-10', '2022-12-11', '2022-12-12', '2022-12-13', '2022-12-14', '2022-12-15'],
price=[23, 25, 21, None, None, None]))
tableB = pd.DataFrame(dict(
date= ['2022-12-10', '2022-12-11', '2022-12-12', '2022-12-13', '2022-12-14', '2022-12-15'],
rollingsum=[0.45, 0.55, 0.51, 0.49, 0.48, 0.47]))
display(tableA, tableB)
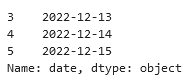
Show what you tried, even if it's broken. If we can copy/paste it, we can help you quick:
no_price = tableA.price.isna()
dates_to_remove = tableA[no_price].date
dates_to_remove
import numpy as np
to_remove = tableB.date.isin(dates_to_remove)
tableB.loc[to_remove, 'rollingsum'] = np.nan # Prefer using .loc to modify the data!
tableB