I have a following dataset:
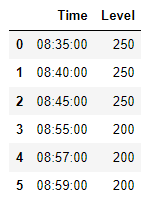
I would like to get a result as follows:
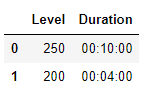
The goal is to calculate duration per "Level" column.
Dataset:
import pandas as pd
from datetime import datetime, date
data = {'Time': ["08:35:00", "08:40:00", "08:45:00", "08:55:00", "08:57:00", "08:59:00"],
'Level': [250, 250, 250, 200, 200, 200]}
df = pd.DataFrame(data)
df['Time'] = pd.to_datetime(df['Time'],format= '%H:%M:%S' ).dt.time
Difference between two datetimes i am able to calculate with the code:
t1 = df['Time'].iloc[0]
t2 = df['Time'].iloc[1]
c = datetime.combine(date.today(), t2) - datetime.combine(date.today(), t1)
But i am not able to "automate" the calculation. This code works the only for integers.
df2 = df.groupby('Level').apply(lambda x: x.Time.max() - x.Time.min())
CodePudding user response:
If you keep the date part of Time, the calculation is a lot easier:
df = pd.DataFrame(data)
# Keep the date part, even though it's meaningless
df["Time"] = pd.to_datetime(df["Time"], format="%H:%M:%S")
def to_string(duration: pd.Timedelta) -> str:
total = duration.total_seconds()
hours, remainder = divmod(total, 3600)
minutes, seconds = divmod(remainder, 60)
return f"{hours:02.0f}:{minutes:02.0f}:{seconds:02.0f}"
level = df["Level"]
# CAUTION: avoid calling to_string until the very last step,
# when you need to display your result. There's not many
# calculations you can do with strings.
df["Time"].groupby(level).diff().groupby(level).sum().apply(to_string)