I'm trying to generate a transcription from an audio file using pydub and speech_recognition libraries. I'm trying to do this through a GUI made in Tkinter, in which I would like to show the transcription asynchronously. However, something doesn't work in my code because the GUI keeps freezing while generating the transcription.
Here is the code:
import customtkinter
import asyncio
from tkinter import filedialog
from async_tkinter_loop import async_handler, async_mainloop
import speech_recognition as sr
import os
from pathlib import Path
from pydub import AudioSegment
from pydub.silence import split_on_silence
class App(customtkinter.CTk):
def __init__(self):
super().__init__()
self.filepath = None
self.transcription = None
self.grid_rowconfigure(2, weight=1)
self.btn_select_file = customtkinter.CTkButton(
self, text="Select audio file", command=self.open_file
)
self.btn_select_file.grid(row=0, column=0, padx=20, pady=30)
self.btn_generate_text = customtkinter.CTkButton(
self,
fg_color="green",
text="Generate text",
command=async_handler(self.get_transcription)
)
self.btn_generate_text.grid(row=1, column=0, padx=20, pady=30)
self.tbx_transcription = customtkinter.CTkTextbox(self, wrap="word")
self.tbx_transcription.grid(row=2, column=0, padx=20, pady=20, sticky="nsew")
def open_file(self):
# Open the file dialog
filepath = filedialog.askopenfilename(
initialdir="/",
title="Select a file",
filetypes=[("Audio files", ["*.mp3", "*.wav", "*.ogg", "*.opus", "*.mpeg"])]
)
if filepath:
self.filepath = filepath
async def get_transcription(self):
if not self.filepath:
self.tbx_transcription.insert(
"0.0",
"Error: No audio file selected, please select one before generating text."
)
return
# Create a task to get the transcription
task = [asyncio.create_task(self.generate_transcription(self.filepath))]
completed, pending = await asyncio.wait(task)
self.transcription = [task.result() for task in completed]
# Display the transcription
self.tbx_transcription.insert("0.0", self.transcription)
@staticmethod
async def generate_transcription(filepath):
"""
Splitting a large audio file into chunks
and applying speech recognition on each of these chunks
"""
# create a speech recognition object
r = sr.Recognizer()
# open the audio file using pydub
content_type = Path(filepath).suffix
if "wav" in content_type:
sound = AudioSegment.from_wav(filepath)
elif "ogg" in content_type or "opus" in content_type:
sound = AudioSegment.from_ogg(filepath)
elif "mp3" in content_type or "mpeg" in content_type:
sound = AudioSegment.from_mp3(filepath)
# split audio sound where silence is 700 miliseconds or more and get chunks
chunks = split_on_silence(
sound,
# experiment with this value for your target audio file
min_silence_len=500,
# adjust this per requirement
silence_thresh=sound.dBFS - 14,
# keep the silence for 1 second, adjustable as well
keep_silence=500,
)
folder_name = "audio-chunks"
# create a directory to store the audio chunks
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
whole_text = ""
# process each chunk
for i, audio_chunk in enumerate(chunks, start=1):
# export audio chunk and save it in the `folder_name` directory.
chunk_filename = os.path.join(folder_name, f"chunk{i}.wav")
audio_chunk.export(chunk_filename, format="wav")
# recognize the chunk
with sr.AudioFile(chunk_filename) as source:
audio_listened = r.record(source)
# try converting it to text
try:
text = r.recognize_google(audio_listened, language="es")
except sr.UnknownValueError as e:
print("Error:", str(e))
else:
text = f"{text.capitalize()}. "
whole_text = text
# return the text for all chunks detected
return whole_text
if __name__ == "__main__":
app = App()
async_mainloop(app)
I tried to use async_tkinter_loop library out of desperation, but it's not mandatory to use it.
EDIT: I've tried httpSteve's solution but the GUI keeps freezing, just as the code that I've provided above. Here is a gif that represents the undisired behaviour of the app.
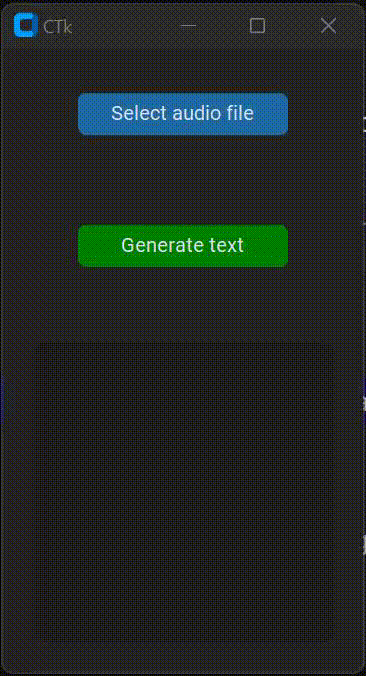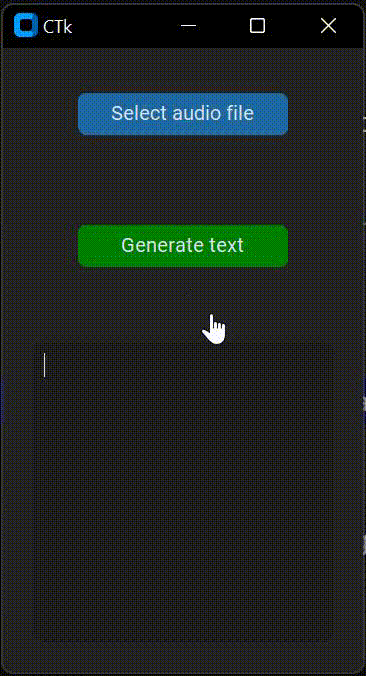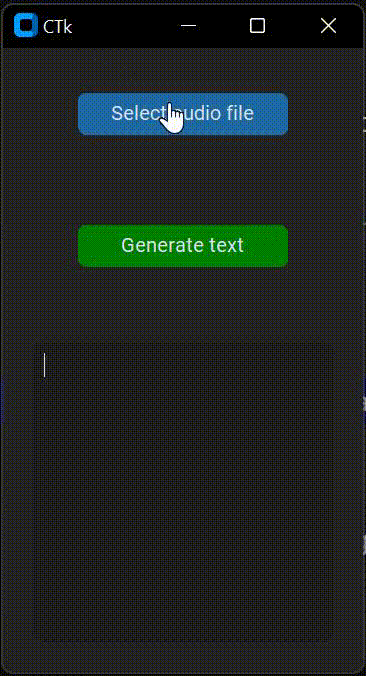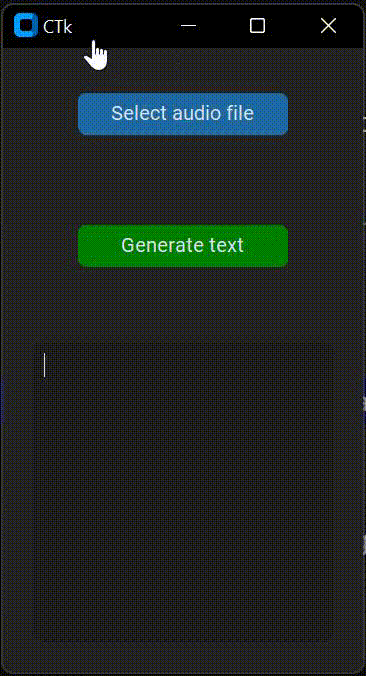
It may not be appreciated, but I try to move the window and click on the buttons without any response. The GUI won't respond until the transcription is generated.
CodePudding user response:
It looks like the problem is that the get_transcription method is running synchronously and blocking the Tkinter main loop, causing the GUI to freeze. To fix this, you should use the await keyword inside the get_transcription method to run the generate_transcription coroutine asynchronously. Also, you can use after method of Tkinter to update the textbox after the transcription is completed.
Here is the updated code:
class App(customtkinter.CTk):
def __init__(self):
# ...
self.btn_generate_text = customtkinter.CTkButton(
self,
fg_color="green",
text="Generate text",
command=self.get_transcription
)
self.btn_generate_text.grid(row=1, column=0, padx=20, pady=30)
# ...
def get_transcription(self):
if not self.filepath:
self.tbx_transcription.insert(
"0.0",
"Error: No audio file selected, please select one before generating text."
)
return
asyncio.create_task(self._get_transcription())
async def _get_transcription(self):
self.transcription = await self.generate_transcription(self.filepath)
self.tbx_transcription.insert("0.0", self.transcription)
This way the generate_transcription coroutine runs in the background, while the Tkinter main loop continues to run and update the GUI.
CodePudding user response:
I've finally managed to prevent the GUI from freezing thanks to threading. The key here is to use
threading.Thread(
target=lambda loop: loop.run_until_complete(self.async_get_transcription()),
args=(asyncio.new_event_loop(),)
).start()
and passing command=lambda: self.get_transcription() when creating the self.btn_generate_text object.
Here is the fixed code:
import asyncio
import customtkinter
import threading
from tkinter import filedialog
import speech_recognition as sr
import os
from pathlib import Path
from pydub import AudioSegment
from pydub.silence import split_on_silence
class App(customtkinter.CTk):
def __init__(self):
super().__init__()
self.filepath = None
self.transcription = None
self.grid_rowconfigure(2, weight=1)
self.btn_select_file = customtkinter.CTkButton(
self,
text="Select audio file",
command=self.open_file
)
self.btn_select_file.grid(row=0, column=0, padx=20, pady=30)
self.btn_generate_text = customtkinter.CTkButton(
self,
fg_color="green",
text="Generate text",
command=lambda: self.get_transcription()
)
self.btn_generate_text.grid(row=1, column=0, padx=20, pady=30)
self.tbx_transcription = customtkinter.CTkTextbox(self, wrap="word")
self.tbx_transcription.grid(row=2, column=0, padx=20, pady=20, sticky="nsew")
def open_file(self):
# Open the file dialog
filepath = filedialog.askopenfilename(
initialdir="/",
title="Select a file",
filetypes=[("Audio files", ["*.mp3", "*.wav", "*.ogg", "*.opus", "*.mpeg"])]
)
if filepath:
self.filepath = filepath
def get_transcription(self):
if not self.filepath:
self.tbx_transcription.insert(
"0.0",
"Error: No audio file selected, please select one before generating text."
)
return
threading.Thread(
target=lambda loop: loop.run_until_complete(self.async_get_transcription()),
args=(asyncio.new_event_loop(),)
).start()
self.progressbar_1 = customtkinter.CTkProgressBar(self)
self.progressbar_1.grid(row=2, column=0, padx=40, pady=0, sticky="ew")
self.progressbar_1.configure(mode="indeterminnate")
self.progressbar_1.start()
async def async_get_transcription(self):
self.transcription = await self.generate_transcription(self.filepath)
self.progressbar_1.grid_forget()
self.tbx_transcription.insert("0.0", self.transcription)
@staticmethod
async def generate_transcription(filepath):
"""
Splitting a large audio file into chunks
and applying speech recognition on each of these chunks
"""
# create a speech recognition object
r = sr.Recognizer()
# open the audio file using pydub
content_type = Path(filepath).suffix
if "wav" in content_type:
sound = AudioSegment.from_wav(filepath)
elif "ogg" in content_type or "opus" in content_type:
sound = AudioSegment.from_ogg(filepath)
elif "mp3" in content_type or "mpeg" in content_type:
sound = AudioSegment.from_mp3(filepath)
# split audio sound where silence is 700 miliseconds or more and get chunks
chunks = split_on_silence(
sound,
# experiment with this value for your target audio file
min_silence_len=500,
# adjust this per requirement
silence_thresh=sound.dBFS - 14,
# keep the silence for 1 second, adjustable as well
keep_silence=500,
)
folder_name = "audio-chunks"
# create a directory to store the audio chunks
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
whole_text = ""
# process each chunk
for i, audio_chunk in enumerate(chunks, start=1):
# export audio chunk and save it in the `folder_name` directory.
chunk_filename = os.path.join(folder_name, f"chunk{i}.wav")
audio_chunk.export(chunk_filename, format="wav")
# recognize the chunk
with sr.AudioFile(chunk_filename) as source:
audio_listened = r.record(source)
# try converting it to text
try:
text = r.recognize_google(audio_listened, language="es")
except sr.UnknownValueError as e:
print("Error:", str(e))
else:
text = f"{text.capitalize()}. "
whole_text = text
# return the text for all chunks detected
return whole_text
if __name__ == "__main__":
app = App()
app.mainloop()