Hello everyone so I made this cnn model.
My data:
Train folder->30 classes->800 images each->24000 all together
Validation folder->30 classes->100 images each->3000 all together
Test folder->30 classes -> 100 images each -> 3000 all together
-I've applied data augmentation. ( on the train data)
-I got 5 conv layers with filters 32->64->128->128->128
each with maxpooling and batch normalization
-Added dropout 0.5 after flattening layers
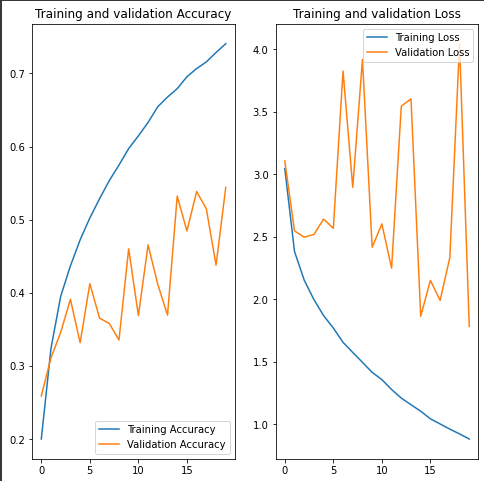
Train part looks good. Validation part has a lot of 'jumps' though. Does it overfit?
Is there any way to fix this and make validation part more stable?
Note: I plann to increase epochs on my final model I'm just experimenting to see what works best since the model takes a lot of time in order to train. So for now I train with 20 epochs.
CodePudding user response:
the answer is yes. The so-called 'jumps' in the validation part may indicate that the model is not generalizing well to the validation data and therefore your model might be overfitting. to fix this you can use the following:
- Increasing the size of your training set
- Regularization techniques
- Early stopping
- Reduce the complexity of your model
- Use different hyperparameters like learning rate
CodePudding user response:
I've applied data augmentation (on the train data).
What does this mean? What kind of data did you add and how much? You might think I'm nitpicking, but if the distribution of the augmented data is different enough from the original data, then this will indeed cause your model to generalize poorly to the validation set.
Increasing your epochs isn't going to help here, your training loss is already decreasing reasonably. Training your model for longer is a good step if the validation loss is also decreasing nicely, but that's obviously not the case.
Some things I would personally try:
- Try decreasing the learning rate.
- Try training the model without the augmented data and see how the validation loss behaves.
- Try splitting the augmented data so that it's also contained in the validation set and see how the model behaves.