The code which I am using below is helping me to compare the files and find the difference as a CSV File.
But the result which I get in a CSV files, are randomized set of lines extracted from both files, or not in the sequence as in the documents. How can I fix this? Is there any better way to compare PDFs?
`from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
from itertools import chain
import pandas as pd
from time import sleep
from tqdm import tqdm
# List of pdf files to process
pdf_files = ['file1.pdf', 'file2.pdf']
# Create a list to store the text from each PDF
pdf1_text = []
pdf2_text = []
# Iterate through each pdf file
for pdf_file in tqdm(pdf_files):
# Open the pdf file
with open(pdf_file, 'rb') as pdf_now:
# Extract text using pdfminer
rsrcmgr = PDFResourceManager()
sio = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, sio, codec=codec, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(pdf_now, set()):
interpreter.process_page(page)
text = sio.getvalue()
text = text.split('\n')
if pdf_file == pdf_files[0]:
pdf1_text.append(text)
else:
pdf2_text.append(text)
device.close()
sio.close()
sleep(20)
pdf1_text = list(chain.from_iterable(pdf1_text))
pdf2_text = list(chain.from_iterable(pdf2_text))
differences = set(pdf1_text).symmetric_difference(pdf2_text)
## Create a new dataframe to hold the differences
differences_df = pd.DataFrame(columns=['pdf1_text', 'pdf2_text'])
# Iterate through the differences and add them to the dataframe
for difference in differences:
# Create a new row in the dataframe with the difference from pdf1 and pdf2
differences_df = differences_df.append({'pdf1_text': difference if difference in pdf1_text else '',
'pdf2_text': difference if difference in pdf2_text else ''}, ignore_index=True)
# Write the dataframe to an excel sheet
differences_df = differences_df.applymap(lambda x: x.encode('unicode_escape').decode('utf-8') if isinstance(x, str) else x)
differences_df.to_excel('differences.xlsx', index=False, engine='openpyxl')`
CodePudding user response:
The following snippet generates a list of sorted text lines in a document.
Please note that package PyMuPDF supports PDF and half a dozen of other document types (XPS, EPUB, MOBI, and more). So that same code will work with any of these.
import fitz # package PyMuPDF
def sorted_lines(filename): # returns sorted text lines
lines = [] # the result
doc = fitz.open(filename)
for page in doc:
page_lines = [] # lines on this page
all_text = page.get_text("dict", flags=fitz.TEXTFLAGS_TEXT)
for block in all_text["blocks"]:
for line in block["lines"]:
text = "".join([span["text"] for span in line["spans"]])
bbox = fitz.Rect(line["bbox"]) # the wrapping rectangle
# append line text and its top-left coord
page_lines.append((bbox.y0, bbox.x0, text))
# sort the page lines by vertical, then by horizontal coord
page_lines.sort(key=lambda l: (l[0], l[1]))
lines.append(page_lines) # append to lines of the document
return lines
# make lists of sorted lines for the two documents
lines1 = sorted_lines(filename1)
lines2 = sorted_lines(filename2)
# now do your comparison / diff of the lines
CodePudding user response:
There are unlimited reasons why two pdf of same size can differ in behaviour even if content is identical on screen or printer. likewise two different files can be able to produce 100% identical ink or pixel placements. So comparison can be problematic.
Here two files should output identical text:-
>pdftotext style1.pdf -
Syntax Error: Unknown font tag ''
Syntax Error (266): No font in show
Syntax Error: Can't get Fields array<0a>
but another copy with a minor variation
>pdftotext style2.pdf -
Hello World!
For controlled comparison of two PDFs then MuPDF or several other libraries are good for customised query, however, if all you need is the fastest text comparison of a numbered page (or all text) it is quicker to write a one line command for pdftotext extract and another for file compare. However in this deliberate illustration of pitfalls, that first file needs a tweak to be brought into line.
using a raw compare is not much use as pdfs often differ unless virtually identical
fc /A /20 style1.pdf style2.pdf && echo same || echo different
Comparing files style1.pdf and STYLE2.PDF
***** style1.pdf
%PDF-1.0
...
endobj
***** STYLE2.PDF
%PDF-1.0
...
endobj
*****
***** style1.pdf
endobj
...
%%EOF
***** STYLE2.PDF
endobj
...
%%EOF
*****
different
So after correction of the first file
>pdftotext style1(fixed).pdf && pdftotext style2.pdf
>fc /A /20 style1(fixed).txt style2.txt && echo same || echo different
Comparing files style1(fixed).txt and STYLE2.TXT
FC: no differences encountered
same
However all is not what it seems :-
Placement style and scale differ
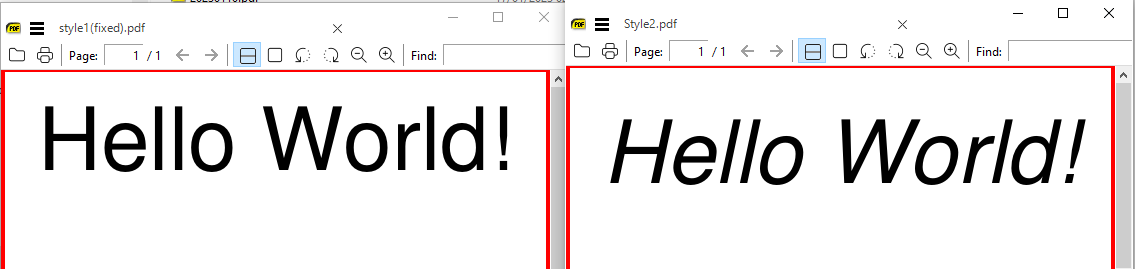
Thus the most conclusive way to test both files for differences is :-
To use text compare for one part of result and a graphical render of both files for the second opinion.