I have a pyspark dataframe with columns "A", "B",and "C","D". I want to add a column with mean of rows. But the condition is that the column names for which mean need to be calculated (at row level) should be taken from a list l=["A","C"].
reason for the list is that the column names and number might vary and hence I need it to be flexible. for eg. I might want mean at row level for cols l=["A","B","C"] or just l=["A","D"].
Finally I want this mean column to be appended to the original pyspark dataframe.
how do I code this in pyspark?
CodePudding user response:
When you say you want the mean, I assume that you want Arithmetic mean :
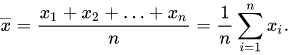
In that case, that's really simple. You can create a function like this :
from pyspark.sql import functions as F
def arithmetic_mean(*cols):
return sum(F.col(col) for col in cols)/len(cols)
Assuming df is you dataframe, you simply use it like this:
df.withColumn("mean", arithmetic_mean("A", "C"))