I have a datafrane like this:
df = data.frame (Ref = c("1", "2", "3", "4"),
start_date = c("01/01/20", "02/04/21", NA, NA),
text = c("foo", NA, "bar", "foo"),
value= c(1000, 7000, 500, 200)
)
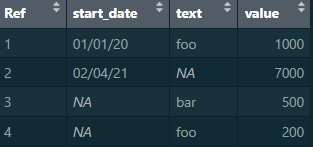
I want a dataframe that counts the number of NA or BLANK in a column and totals the value column.
So far, I have the following code:
naDF = colSums(is.na(df)|df == '')
naDF = data.frame(as.list(naDF))
naDF = melt(naDF)
Which produces this:
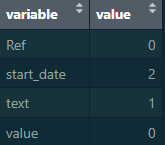
But I want another column which totals the value column for those counts e.g.
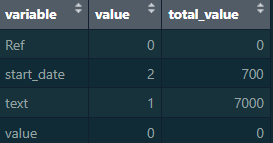
Any advice? Thank you
CodePudding user response:
Or with base R
m1 <- df$value * NA^!is.na(df)
data.frame(total_value = colSums(m1, na.rm = TRUE),
value= colSums(!is.na(m1)))
-output
total_value value
Ref 0 0
start_date 700 2
text 7000 1
value 0 0
CodePudding user response:
a <- df$value * is.na(df)
data.frame(value = colSums(a>0), total_value = colSums(a))
value total_value
Ref 0 0
start_date 2 700
text 1 7000
value 0 0
CodePudding user response:
library(tidyverse)
df %>%
mutate(value1 = value) %>%
pivot_longer(-value1, values_to = 'res',
values_transform = as.character)%>%
group_by(name) %>%
summarise(value = sum(is.na(res)),
total_value = sum(is.na(res)*value1))
# A tibble: 4 × 3
name value total_value
<chr> <int> <dbl>
1 Ref 0 0
2 start_date 2 700
3 text 1 7000
4 value 0 0
CodePudding user response:
We may use
library(dplyr)
library(tidyr)
df %>%
mutate(across(everything(), ~ sum(value[is.na(.x)]) * NA^is.na(.x))) %>%
pivot_longer(everything(), names_to = 'variable', values_to = 'total_value') %>%
group_by(variable) %>%
summarise(value = sum(is.na(total_value)), total_value = first(total_value))
-output
# A tibble: 4 × 3
variable value total_value
<chr> <int> <dbl>
1 Ref 0 0
2 start_date 2 700
3 text 1 7000
4 value 0 0
CodePudding user response:
Here is another tidyverse approach using purrr package to count the NAs in each column:
library(purrr)
library(tidyr)
library(dplyr)
df %>%
purrr::map_df(~sum(is.na(.))) %>%
pivot_longer(everything()) %>%
bind_cols(total_value = df$value)
name value total_value
<chr> <int> <dbl>
1 Ref 0 1000
2 start_date 2 7000
3 text 1 500
4 value 0 200