Is there a tidyverse way to combine rows of the same group replacing certain values:
I don't want a pivot solution!
This is my dataframe:
df <- structure(list(A = c(1L, 1L, 2L, 3L, 4L, 5L), B = c("a", "a",
"b", "c", "d", "e"), C = c("u", "t", "t", "u", "t", "t"), D = c("t",
"u", "u", "t", "u", "u"), E = c("t", "t", "u", "u", "u", "u")),
class = "data.frame", row.names = c(NA, -6L))
A B C D E
1 1 a u t t
2 1 a t u t
3 2 b t u u
4 3 c u t u
5 4 d t u u
6 5 e t u u
My desired output:
A B C D E
1 1 a u u t
2 2 b t u u
3 3 c u t u
4 4 d t u u
5 5 e t u u
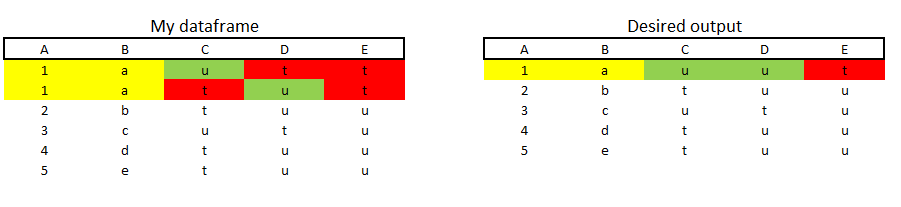
Row 1 and 2 have the same group 1 and a (Column A and B) ->
This group should be combined to one row 1 a replacing t by u in column C to E
Lessons studied:
combine rows in data frame containing NA to make complete row
Merging two rows with some having missing values in R
CodePudding user response:
We can group by 'A', 'B', summarise across the columns, order the values so that 'u' will return before other values and select the first element
library(dplyr)
df %>%
group_by(A, B) %>%
summarise(across(everything(),
~ first(.[order(. != 'u')])), .groups = 'drop')
-output
# A tibble: 5 x 5
A B C D E
<int> <chr> <chr> <chr> <chr>
1 1 a u u t
2 2 b t u u
3 3 c u t u
4 4 d t u u
5 5 e t u u