Background
I've got a dataset d on use of services for members (shown as ID) of an organization. Here's a toy example:
d <- data.frame(ID = c("a","a","b","b"),
dob = as.Date(c("2004-04-17","2004-04-17","2009-04-24","2009-04-24")),
service_date = as.Date(c("2018-01-01","2019-07-12","2014-12-23","2016-04-27")),stringsAsFactors=FALSE)
It looks like this:
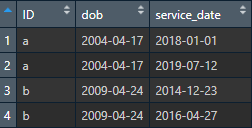
Besides ID, it's got a date of birth dob and dates of service service_date for each time the member has used the organization's service.
Problem
I'd like to add a new column age_first_record that represents -- you guessed it -- a member's age at their first service_date. Ideally, this figure should be in years, not days. So if you're 13 years and one month old, the figure would be 13.08. The number should repeat within ID, too, so whatever that ID's age at their first service_date was, that's the number that goes in every row for that ID.
What I'm looking for is something that looks like this:
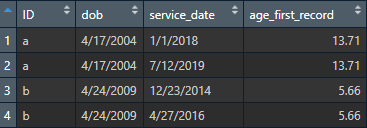
What I've Tried
So far, I'm messing with the MIN function a bit, like so:
d <- d %>%
mutate(age_first_rec = min(d$service_date-d$dob))
But I can't seem to (a) get it work "within" each ID and (b) express it in years, not days. I'm not too familiar with working with datetime objects, so forgive the clumsiness here.
Any help is much appreciated!
CodePudding user response:
We can use difftime to get the difference in days and divide by 365
library(dplyr)
d %>%
group_by(ID) %>%
mutate(age_first_record = as.numeric(difftime(min(service_date),
dob, unit = 'day')/365)) %>%
ungroup
-output
# A tibble: 4 x 4
ID dob service_date age_first_record
<chr> <date> <date> <dbl>
1 a 2004-04-17 2018-01-01 13.7
2 a 2004-04-17 2019-07-12 13.7
3 b 2009-04-24 2014-12-23 5.67
4 b 2009-04-24 2016-04-27 5.67