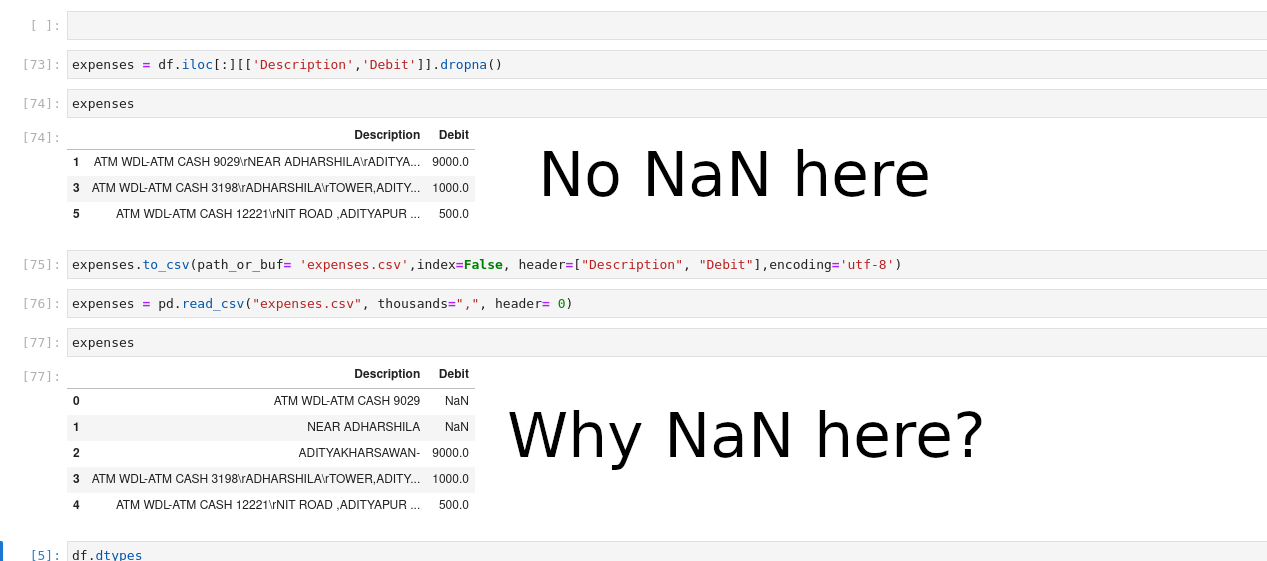
I am trying to put a dataframe into a csv file and then access it. But by doing so the NaN values are showing up and the data are misaligned.
expenses = df.iloc[:][['Description','Debit']].dropna()
Here, i am trying to get the Description and debit column where there is no NaN data.
expenses.to_csv(path_or_buf= 'expenses.csv',index=False, header=["Description", "Debit"],encoding='utf-8')
expenses = pd.read_csv("expenses.csv", thousands=",", header= 0)
And then saving that dataframe into expenses and trying to access the same csv file but the content is misaligned. When I open the csv file its correct.
Here, is a screenshot to help you understand:
CodePudding user response:
That is because, by default the inplace=False, when you use dropna , do:
df.dropna(subset=['Description','Debit'], inplace=True)
It should work. Your df, in this case, should have dropped the NaN values on these two columns.