Python newbie here with a lot of bad habits from VBA. I've devised a long, complicated way to achieve what I need but I'm sure there's a much better, Pythonic way to do this and would really appreciate some pointers. Basically, I've got a table like this (only much bigger, >5000 rows, which I've imported into a pandas DataFrame from a csv file):
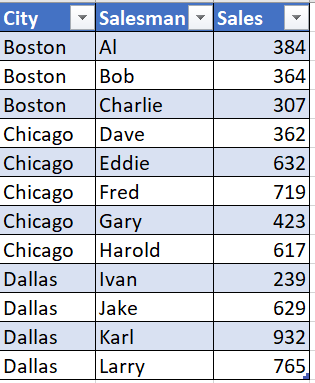
I want to end up with a pivoted DataFrame that concatenates the Salesman names and sums up the Sales figures, like this:
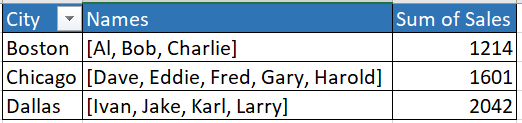
(For reasons I don't need to go into I'd prefer those concatenated names in the form of a list, hence the brackets.)
For the life of me I can't figure out a simple way to do this in pandas. (Should I even use pandas?) I'll spare you the ridiculous code I came up with (unless someone really wants to see it, for a laugh), but basically I ended up creating various lists and iterating through them (like I would in VBA arrays) to put together what I wanted...don't ask.
I can easily do something like this
df_pivot = pd.pivot_table(df,index=['City'],values=['Sales'],aggfunc=np.sum)
to get the 1st and 3rd columns, but can't figure out how to Pythonically get the 2nd column. What's the sensible way to do this? Thanks!
CodePudding user response:
Use GroupBy.agg with named aggregations:
df.groupby('City').agg(Names = ('Salesman', list), Sum_Sales=('Sales', 'sum'))
Or:
df.groupby('City').agg(**{'Names': ('Salesman', list), 'Sum of Sales':('Sales', 'sum')})
CodePudding user response:
Use groupby with agg:
df.groupby('City').agg({'Salesman': list, 'Sales': sum})
Or with column names:
df.groupby('City').agg({'Salesman': list, 'Sales': sum})
.rename({'Salesman': 'Names', 'Sales': 'Sum of Sales'}, axis=1)