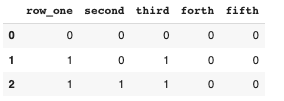
I want to select columns where the sum of each column is more than 1
What I have tried:
df_1 = pd.DataFrame((df.sum(axis=0) >=1))
df[df_1[df_1[0]==True].index]
Is there any more efficient method?
CodePudding user response:
Use DataFrame.loc with : for select all rows and columns by mask if performance is important:
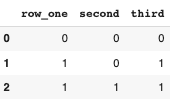
df = df.loc[:, df.sum() >=1]
print (df)
row_one second third
0 0 0 0
1 1 0 1
2 1 1 1
Alternative:
df = df.loc[:, df.to_numpy().sum(axis=0) >=1]
CodePudding user response:
Or use with transposing:
>>> df.T[df.sum() >= 1].T
row_one second third
0 0 0 0
1 1 0 1
2 1 1 1
>>>
That filters the transposed dataframe, that behaves regularly.
Or you could get the column names with:
>>> df[df.sum()[df.sum() >= 1].index]
row_one second third
0 0 0 0
1 1 0 1
2 1 1 1
>>>
Or with drop:
>>> df.drop(df.columns[df.sum() < 1], axis=1)
row_one second third
0 0 0 0
1 1 0 1
2 1 1 1
>>>