I try to impute missing values in one column by sampling from a given discrete distribution. I chose gender as a simple example. This is my attempt:
library(dplyr)
set.seed(42)
df <- data.frame(
gender = c("f", "m", "m", NA, NA, NA, NA, NA, NA, NA, NA)
)
df
df <- df %>%
mutate(
derived_gender_of_casualty = ifelse(
is.na(gender)
, sample(x = c("m", "f"), prob = c(0.9, 0.1))
, as.character(gender))
)
df
It creates:
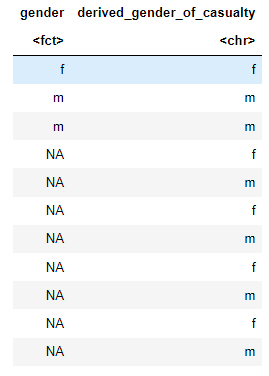
However, it does not look right. The genders are uniformly distributed. I would expect there to be more males given the probability of 0.9 (this is not meant to be controversial - in hisight I should have picked another example haha!!!).
Any ideas? Thanks!
CodePudding user response:
Let's see what sample(x = c("m", "f"), prob = c(0.9, 0.1)) returns
sample(x = c("m", "f"), prob = c(0.9, 0.1))
#[1] "m" "f"
Try this multiple times, do you see any change? Maybe the order gets changed but do you see any effect of 0.9 or 0.1 ? Let's repeat this for 100 times and count number of times 'm' and 'f' occur.
table(replicate(100, sample(x = c("m", "f"), prob = c(0.9, 0.1))))
# f m
#100 100
Still the ratio is the same. By default sample has replace = FALSE and when you don't mention the n, it is same as length of the vector passed so the probability does not matter here. The reason why you get such an output is because sample(x = c("m", "f"), prob = c(0.9, 0.1)) returns two values with both m and f and the same value is recycled throughout.
Solution
library(dplyr)
set.seed(123)
df %>%
mutate(
derived_gender_of_casualty = ifelse(
is.na(gender)
, sample(x = c("m", "f"), n(), prob = c(0.9, 0.1), replace = TRUE)
, as.character(gender))
)
# gender derived_gender_of_casualty
#1 f f
#2 m m
#3 m m
#4 <NA> m
#5 <NA> f
#6 <NA> m
#7 <NA> m
#8 <NA> m
#9 <NA> m
#10 <NA> m
#11 <NA> f
CodePudding user response:
A base R option:
set.seed(42)
df <- data.frame(
gender = c("f", "m", "m", NA, NA, NA, NA, NA, NA, NA, NA)
)
df$gender[is.na(df$gender)] <- sample(x = c("m", "f"),
size = sum(is.na(df$gender)),
prob = c(0.9, 0.1),
replace = TRUE)
df
#> gender
#> 1 f
#> 2 m
#> 3 m
#> 4 f
#> 5 f
#> 6 m
#> 7 m
#> 8 m
#> 9 m
#> 10 m
#> 11 m
Created on 2021-09-24 by the reprex package (v2.0.0)
CodePudding user response:
Adding rowwise in your chain should do it:
df <- df %>%
rowwise %>%
mutate(
derived_gender_of_casualty = ifelse(
is.na(gender)
, sample(x = c("m", "f"), prob = c(0.9, 0.1))
, as.character(gender))
)
df
Here's a little experiment to show that it works. I make df have 1000 rows all missing on gender. The imputed data has Pr(M) approximately = 0.9.
set.seed(42)
df <- data.frame(
gender = rep(NA, 1000)
)
df
df <- df %>%
rowwise %>%
mutate(
derived_gender_of_casualty = ifelse(
is.na(gender)
, sample(x = c("m", "f"), size = 1, prob = c(0.9, 0.1))
, as.character(gender))
)
mean(df$derived_gender_of_casualty == "m")
#[1] 0.899