I'm using Tensorflow 2.5 to train a starGAN network for generating images (128x128 jpeg). I am using tf.keras.preprocessing.image_dataset_from_directory to load the images from the subfolders.
Additionally I am using arguments to maximize loading performance as suggested in various posts and threads such as loadedDataset.cache().repeat.prefetch
I'm also using the num_parallel_calls=tf.data.AUTOTUNE for the mapping functions for post-processing the images after loading.
While training the network on GPU the performance I am getting for GPU Utilization is in the picture attached below.
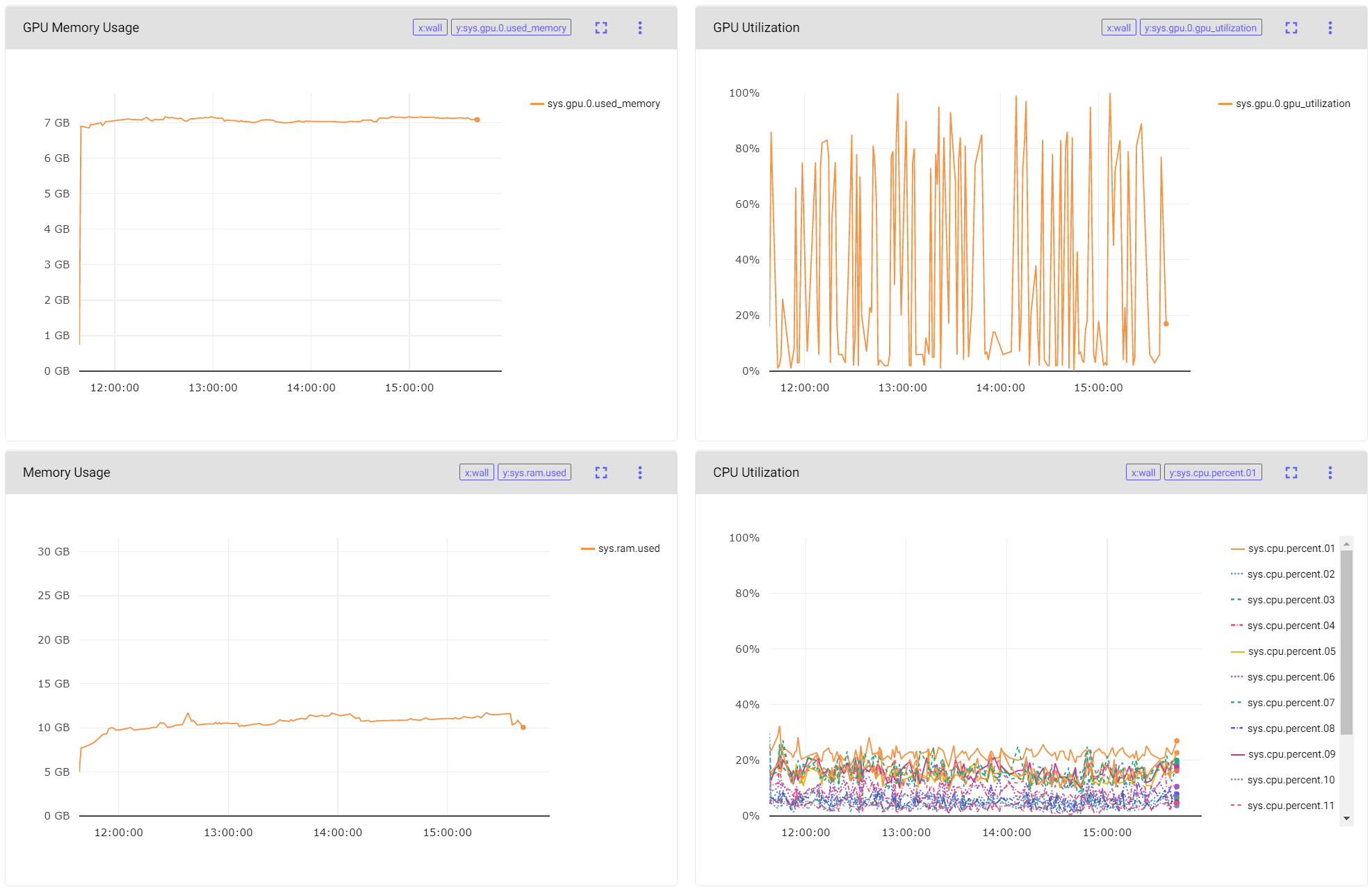
My question regarding this are:
- Is the GPU utlization normal or is it not supposed to be so erratic for traning GANs?
- Is there any way to make this performance more consistent?
- Is there any way to improve the training performance to fully utlize the GPU?
Note that Ive logged my disk I/O also and there is no bottleneck reading/writing from the disk (nvme ssd). The system has 32GB RAM and a RTX3070 with 8GB Vram. I have tried the running it on colab also; but the performance was similarly erratic.
CodePudding user response:
It is fairly normal for utilization to be erratic like for any kind of parallelized software, including training GANs. Of course, it would be better if you could fully utilize your GPU, but writing software that does this is challenging and becomes virtually impossible when you are talking about complex applications like GANs.
Let me try to demonstrate with a trivial example. Say you have two threads, threadA and threadB. threadA is running the following python code:
x = some_time_comsuming_task() y = get_y_from_threadB() print(x y)Here threadA is performing lots of calculations to get the value for x, retrieving the value for y, and printing out the sum of
x y. Imagine threadB is also doing some kind of time consuming calculation to generate the value for y. Unless threadA is ready to retrieve y at the exact same time threadB finishes calculating it, you won't have 100% utilization of both threads for the entire duration of the program. And this is just two threads, when you have 100s of threads working together with multiple chained data dependencies, you can see how it becomes exponentially more difficult to eliminate any and all time threads spend waiting on other threads to deliver input to the next step of computation.Trying to make your "performance more consistent" is pointless. Whether your GPU utilization went up and down (like in the graph you shared) or it stayed exactly at the average utilization for the entire execution would not change the overall execution time, which is probably the actually important metric here. Utilization is mostly useful to identify where you can optimize your code.
Fully utilize? Probably not. As explained in my answer to question one, it's going to be virtually impossible to orchestrate your GAN to completely remove bottlenecks. I would encourage you to try and improve execution time, rather than utilization, when optimizing your GAN. There's no magic setting that you're missing that will completely unlock all of your GPU's potential.