I am just trying to scrape some random news title in a google news page , when i inspect the title of news title i get
Class = mCBkyc JQe2Ld nDgy9d
but when i try with Beautifulsoup this class is not present , it changes in content fetched from response
Class = BNeawe UPmit AP7Wnd
i am aware this might be due to JS but how can i handle it properly
below what i have tried
from bs4 import BeautifulSoup
import requests
content = requests.get(
"https://www.google.com/search?q=beautiful soup get text a&safe=active&rlz=1C1GCEB_enIN960IN960&source=lnms&tbm=nws&sa=X&ved=2ahUKEwjNzsv-iaTzAhX6yzgGHfeBDzgQ_AUoA3oECAEQBQ&biw=1707&bih=770&dpr=1.13").content
soup = BeautifulSoup(content, features="html.parser")
with open("d.txt", "w") as file:
file.write(soup.prettify())
for a in soup.find_all('div', class_='BNeawe vvjwJb AP7Wnd'): # in this line if kept class = mCBkyc JQe2Ld nDgy9d none is returned
print(a)
CodePudding user response:
I dont know what you are actually looking for but:
When you use a selector like:
div[role='text']
example:
soup.select("div[role='text']")
You will get all news on page:
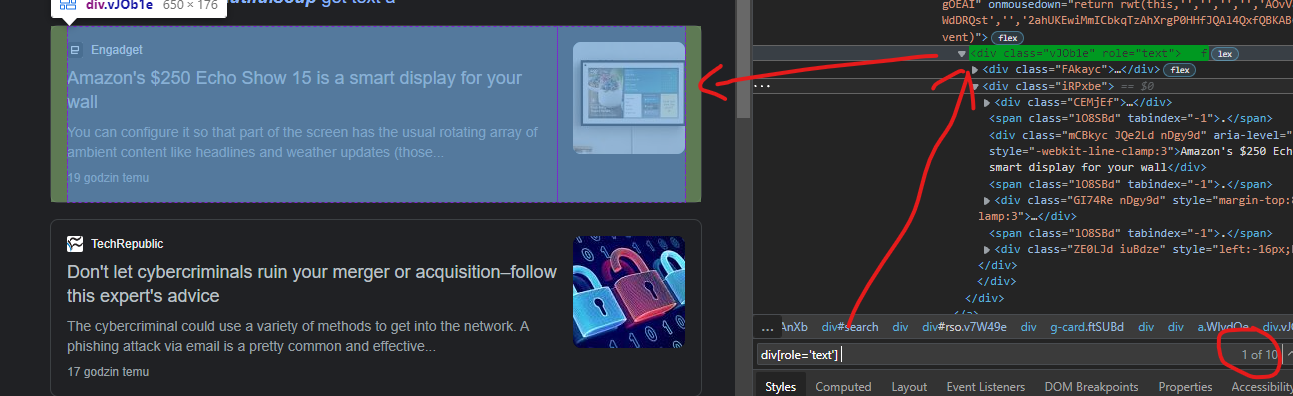
As you can see there are 10 items like this on page (all news in my case). Then you can proceed with rest - finding all needed data in each item.
EDIT:
Unfortunately you can be blocked from doing so. Bcoz of this:

My Advice - use Selenium