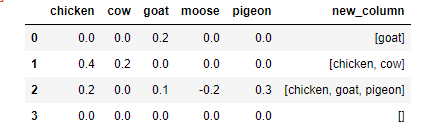
Might sounds like a duplicate question, but it is slightly different than what I have found here. I have the following pandas DF (without the new column), and I want to create the new_column
| chicken | cow | moose | goat | pigeon | new column |
|:--------|:----|:------|:-----|:-------|:---------------------------------|
| 0 | 0 | 0 | 0.2 | 0 | [goat] |
| 0.4 | 0.2 | 0 | 0 | 0 | [chicken, cow] |
| 0.2 | 0 | -0.2 | 0.1 | 0.3 | [chicken, moose, goat, pigeon] |
| 0 | 0 | 0 | 0 | 0 | [ ] |
I was thinking to make an empty column first, and then append the column value in the new cell when != 0. However, haven't been able to find the solution though. I feel it shouldn't be that hard.. any help from the community?
CodePudding user response:
You can compare valeus for not equal to 0 and create joined values by separator added to columns names, last ncessary split for lists:
df['new column'] = df.ne(0).dot(df.columns ',').str[:-1].str.split(',')
Or if performance is important use list comprehension:
cols = df.columns.to_numpy()
df['new column'] = [list(cols[x]) for x in df.ne(0).to_numpy()]
Or if performance is NOT important use apply per axis=1:
df['new column'] = df.ne(0).apply(lambda x: list(x.index[x]), axis=1)
print (df)
chicken cow moose goat pigeon new column
0 0.0 0.0 0.0 0.2 0.0 [goat]
1 0.4 0.2 0.0 0.0 0.0 [chicken, cow]
2 0.2 0.0 -0.2 0.1 0.3 [chicken, moose, goat, pigeon]
3 0.0 0.0 0.0 0.0 0.0 []
CodePudding user response:
I would use this approach.
Define a function that you will apply to every row and filter the pandas series and get the index name.
import pandas as pd
d = {
"chicken":[0, 0.4, 0.2, 0],
"cow":[0, 0.2, 0, 0],
"moose":[0, 0, -0.2, 0],
"goat":[0.2, 0, 0.1, 0],
"pigeon":[0, 0, 0.3, 0]
}
df = pd.DataFrame(data = d)
def get_col_names(row):
return row[row > 0].index.tolist()
df["new_column"] = df.apply(lambda row: get_col_names(row), axis = 1)
df