Say, I need to convert the following formula into python and use it on a data frame. The formula is as follows.
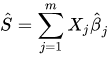
The data frame has got values for Xj and Bj. The data frame looks like the following.
df.head()
type name OR
1 SAP1 11.21
1 SAP1 1301
2 SAP1 0.7578
2 LUF1 1447
2 LUF1 0.7578
1 ANK3 1150
1 ANK3 0.9909
1 ANK3 1535
1 ACR 0.9909
1 ACR 1535
The above data frame has got values for Xj=type and bj=OR from the data frame. I need for each sam The ^S score from the formula
In the end, for each name, I need a single S score.
I have implemented something like this,
def score(df):
df_sum =df[['type','name','OR']].groupby('name').sum().reset_index()
sum =df_sum['type']
OR=df_sum['OR']
score=sum([sum*OR])
return score
The question is I need to get them for each name value single score not many scores for all repeating name values. In the end, I need only 4 rows with 4 score values.
It is possible on small datasets. However, when I give a big data frame with multiple name values for OR and type columns. Then I have multiple scores for the same name
Note: The values in column type are binaries. Hence, I am not sure I am use in grouby to count or sum it
CodePudding user response:
I think if you change the order of opérations you can have the expected result:
1 calculate xi*bi
df['xibi'] =df ['type'] * df['OR']
2 groupby and sum
res=df.groupby('name')['xibi'].sum()