Closed. This question needs to be more
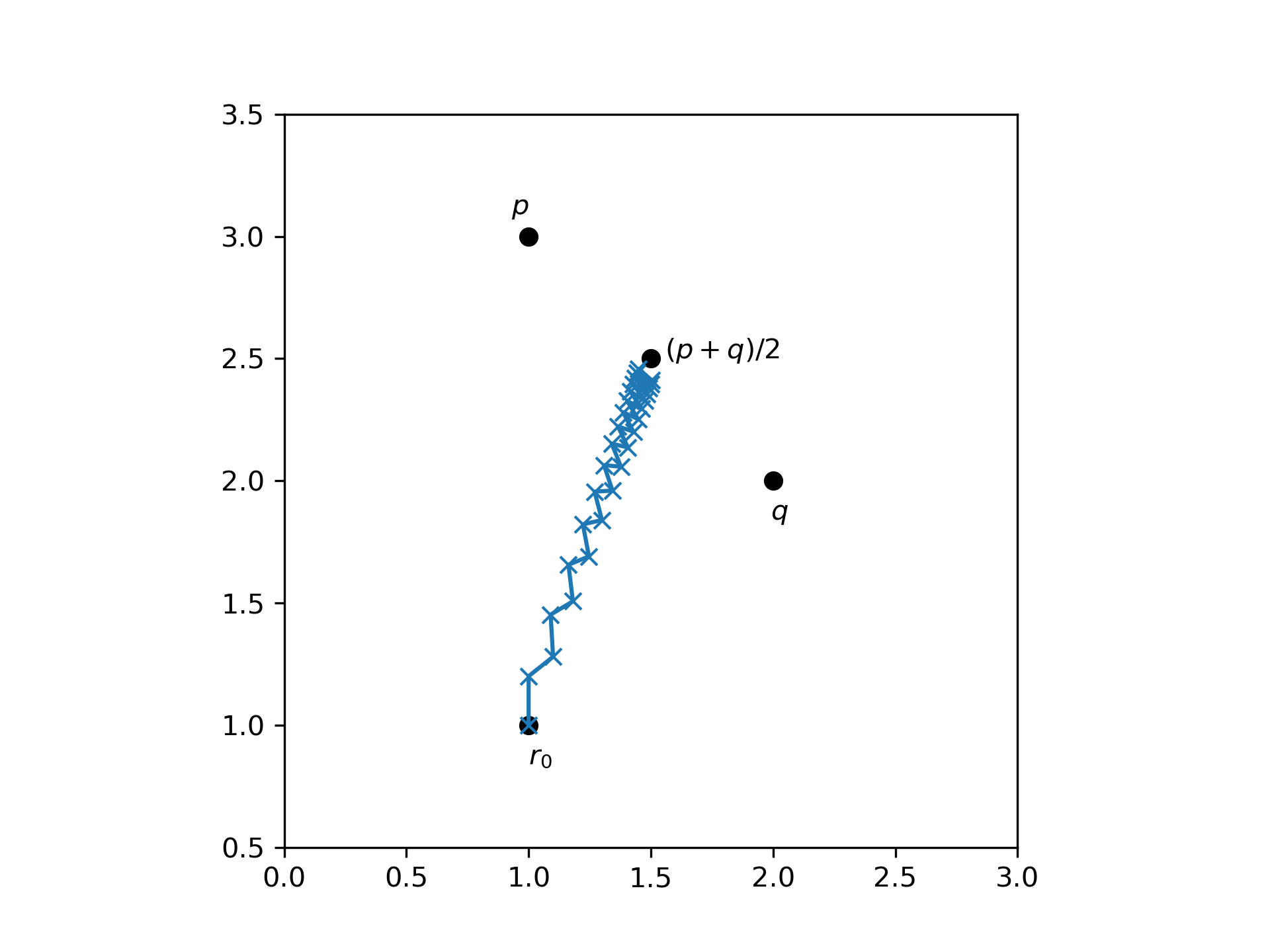
From this example, you can see, which assumptions are made when using SGD. The parameter α has to be chosen small enough such that you are not jumping around wildly, but just move slightly towards the minimum of each batch. If you were to compute the corrections of all batches at once with respect to the same value of r, instead of updating r between each batch, and then applying all corrections at once, you would actually be performing a step of (batch) gradient decent. If α is small, then r does not change significantly when the correction of a single batch is applied. Hence, the effect of computing the corrections of all batches at once is very similar to computing the corrections after each update, and thus (batch) gradient decent and SDG converge to the same local minimum.