For simplicity, I write a simplified example
import pandas as pd
import numpy as np
indices = (1,2,3,4,5,6)
cols = ["id", "region", "weight", "score1", "score2"]
data = (["xxx1", 1, 2, 10, 20], ["xxx2", 2, 5, 6, 8], ["xxx3", 1, 3, 9, 12], ["xxx4", 1, 3, 12, 20], ["xxx5", 1, 5, 5, 30], ["xxx6", 2, 10, 12, 20])
df = df = pd.DataFrame(data, index = indices, columns = cols)
df
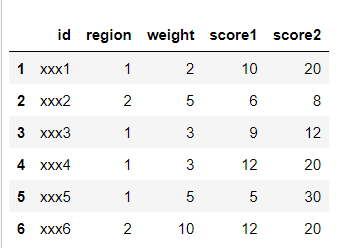
which looks like this
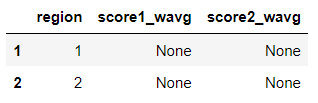
I want to calculate the weighted average score using pandas and numpy packages only, and my ideal result should be a 2x3 table, whose rows are regions they belong to and columns are the weighted average score1 and score2. Below is my attempt
def cal(x, w):
assert len(x) == len(w)
nlist = len(x)
sum_weight = np.sum(w)
weight_total = 0
for i in range(nlist):
weight_total = weight_total x[i] * w[i]
wavg = weight_total / sum_weight
return wavg
However, I think this method is too awkward. I am wondering if there is more convenient way to achieve the same goal. Any hint or help is welcome
the ideal result
CodePudding user response:
Try calculate weighted total and sum of weight separately and then divide:
weighted_total = df.filter(like='score').mul(df.weight, axis=0).groupby(df.region).sum()
sum_weight = df.weight.groupby(df.region).sum()
weighted_total.div(sum_weight, axis=0)
score1 score2
region
1 8.307692 22.0
2 10.000000 16.0
Or in a single groupby:
df.groupby('region').apply(
lambda g: g.filter(like='score').mul(g.weight, axis=0).sum().div(g.weight.sum(), axis=0)
)
score1 score2
region
1 8.307692 22.0
2 10.000000 16.0