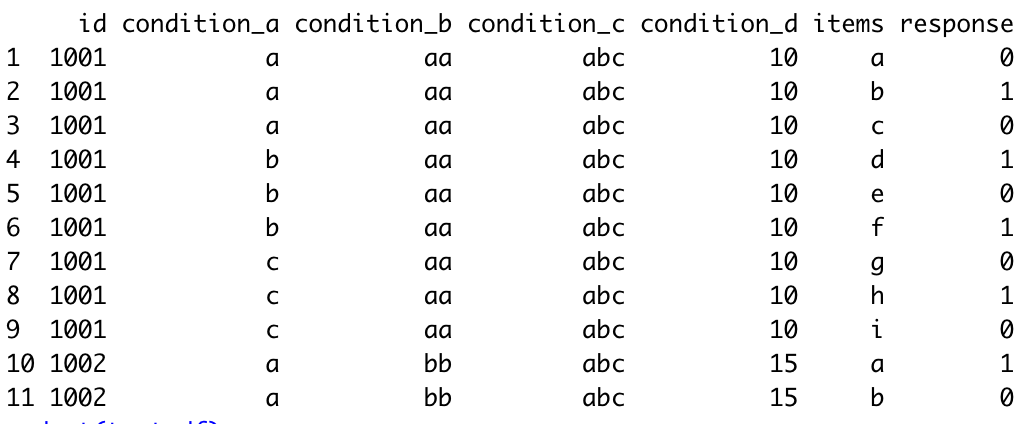
I would like to replace the ids, starting from 1.
The following is one potential resulting dataset I would like to obtain:
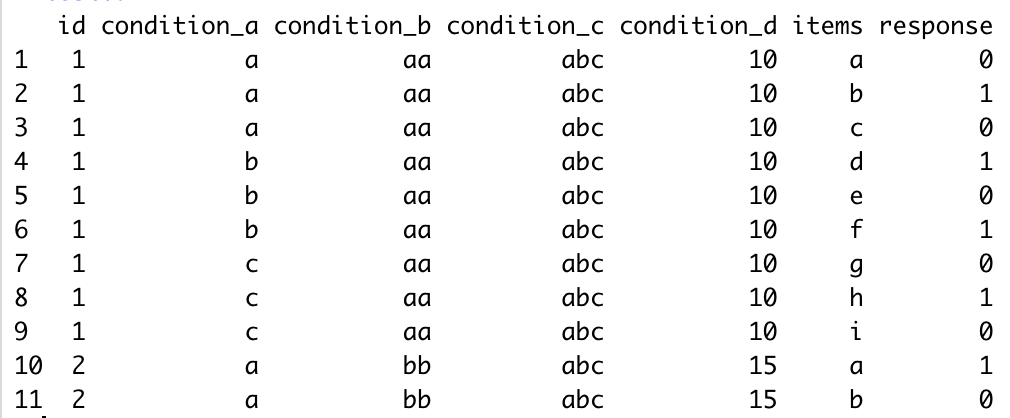
I have been trying to use pivot_longer and pivot_wide for hours, but could not figure out how to do this.
I would appreciate it if you could demonstrate how I can replace the id column with new ids.
Here are some replicable dataset:
structure(list(id = c(1001L, 1001L, 1001L, 1001L, 1001L, 1001L,
1001L, 1001L, 1001L, 1002L, 1002L), condition_a = c("a", "a",
"a", "b", "b", "b", "c", "c", "c", "a", "a"), condition_b = c("aa",
"aa", "aa", "aa", "aa", "aa", "aa", "aa", "aa", "bb", "bb"),
condition_c = c("abc", "abc", "abc", "abc", "abc", "abc",
"abc", "abc", "abc", "abc", "abc"), condition_d = c(10L,
10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 15L, 15L), items = c("a",
"b", "c", "d", "e", "f", "g", "h", "i", "a", "b"), response = c(0L,
1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L)), class = "data.frame", row.names = c(NA,
-11L))
CodePudding user response:
Not sure I fully understand the extent of the transformation you want but if it's just creating new indices starting at one this will do the trick.
library(dplyr)
df3 %>%
group_by(id) %>%
mutate(id = cur_group_id())
CodePudding user response:
You use group_indices along with mutate:
library(tidyverse)
df %>%
mutate(id = group_indices(df, .dots = c('id')))