I am unable to get the links from this website called: 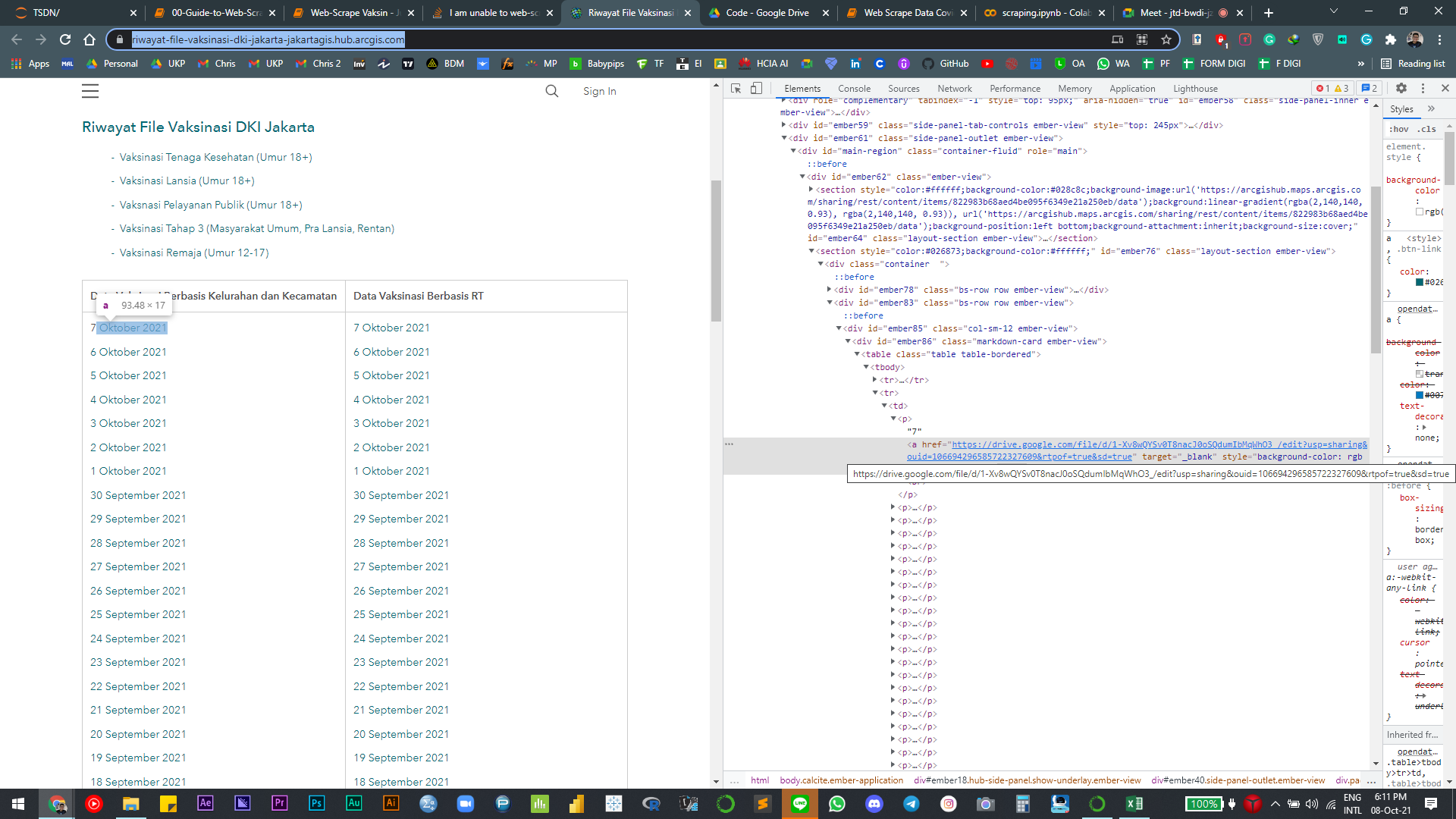
I want to get all of the google drive links from that hyperlinks on the left column
CodePudding user response:
Seleniumsolution:
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
# options.add_argument('--headless')
driver = webdriver.Chrome(options = options)
driver.get("https://riwayat-file-vaksinasi-dki-jakarta-jakartagis.hub.arcgis.com/")
time.sleep(3) # wait for page to download
links = [i.get_attribute('href') for i in driver.find_elements_by_css_selector("td p a")]
print(links)
driver.quit()
If you didn't use Selenium before, do not forget to install chromedriver.
requestsurllib.parsesolution (inspired by the comment of @tromgy)
import requests
import bs4
from urllib.parse import unquote
req = requests.get('https://riwayat-file-vaksinasi-dki-jakarta-jakartagis.hub.arcgis.com/')
soup = bs4.BeautifulSoup(req.text,"lxml")
url = unquote(soup.select_one("script#site-injection").string[23:].strip())
soup = bs4.BeautifulSoup(url,"lxml")
links = [i['href'][2:-2] for i in soup.select("td p a")]
links
If you want to get only the left column of the table, then use td:first-of-type p a as css selector. It simply inspects the first td element and ignore the second (right) one.