I have a list of tuple which looks like this:
data = [(1633098324445950024, 139.55, 15, [14, 37, 41]),
(1633098324445958000, 139.55, 100, [14, 41]),
(1633098324445958498, 139.55, 60, [14, 37, 41]),
(1633098324446013523, 139.55, 52, [14, 37, 41]),
(1633098324472392943, 139.555, 100),
(1633098324478972256, 139.555, 100)]
I am trying to save it in a csv file with:
def save_csv(data, path, filename):
with open(os.path.join(path, str(filename) '_data.csv'), "w") as outfile:
outfile.write("\n".join(f"{r[0]},{r[1]},{r[2]},{r[3]}" for r in data))
save_csv(data, path, filename)
I am getting the IndexError:
outfile.write("\n".join(f"{r[0]},{r[1]},{r[2]},{r[3]}" for r in data))
IndexError: tuple index out of range
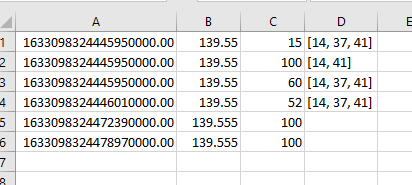
I would like the result looks like this:
CodePudding user response:
import csv
data = [(1633098324445950024, 139.55, 15, [14, 37, 41]),
(1633098324445958000, 139.55, 100, [14, 41]),
(1633098324445958498, 139.55, 60, [14, 37, 41]),
(1633098324446013523, 139.55, 52, [14, 37, 41]),
(1633098324472392943, 139.555, 100),
(1633098324478972256, 139.555, 100)]
with open("csv.csv", "w") as f:
csv_writer = csv.writer(f)
for mytuple in data:
csv_writer.writerow(mytuple)
CodePudding user response:
You have a variable number of columns - r[3] won't always exist. This is a great use case for pandas which will add defaults as needed.
import pandas as pd
data = [(1633098324445950024, 139.55, 15, [14, 37, 41]),
(1633098324445958000, 139.55, 100, [14, 41]),
(1633098324445958498, 139.55, 60, [14, 37, 41]),
(1633098324446013523, 139.55, 52, [14, 37, 41]),
(1633098324472392943, 139.555, 100),
(1633098324478972256, 139.555, 100)]
pd.DataFrame(data).to_csv("test.csv")