I have a big data set with tons of rows. I have one column in that data set with long row values. I want to rename these row values with shorter names and use the previous column values as a part of the name. How can I do this with Pandas?
I have a dataset like this:
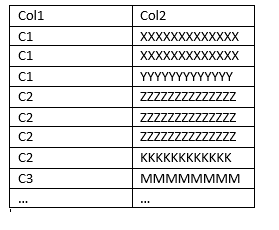
And want an output like this:
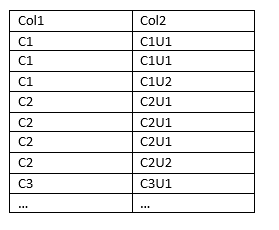
CodePudding user response:
What you are looking for is the pd.factorize function which encodes the different patterns of objects as an enumerated type (with different serial numbers), as follows:
df['Col2'] = df['Col1'] 'U' df.groupby('Col1')['Col2'].transform(lambda x: pd.factorize(x)[0] 1).astype(str)
Since each different value of Col1 need to reset the serial number from 1, we make use of .GroupBy() .transform() to help with this.
Demo
Data Input
data = {'Col1': ['C1', 'C1', 'C1', 'C2', 'C2', 'C2', 'C2', 'C3'],
'Col2': ['XXXXXXXXXXXXXX', 'XXXXXXXXXXXXXX', 'YYYYYYYYYYYYYY', 'ZZZZZZZZZZZZZZ', 'ZZZZZZZZZZZZZZ', 'ZZZZZZZZZZZZZZ', 'KKKKKKKKKKKKKK', 'MMMMMMMMMMMMMM']}
df = pd.DataFrame(data)
print(df)
Col1 Col2
0 C1 XXXXXXXXXXXXXX
1 C1 XXXXXXXXXXXXXX
2 C1 YYYYYYYYYYYYYY
3 C2 ZZZZZZZZZZZZZZ
4 C2 ZZZZZZZZZZZZZZ
5 C2 ZZZZZZZZZZZZZZ
6 C2 KKKKKKKKKKKKKK
7 C3 MMMMMMMMMMMMMM
Output:
print(df)
Col1 Col2
0 C1 C1U1
1 C1 C1U1
2 C1 C1U2
3 C2 C2U1
4 C2 C2U1
5 C2 C2U1
6 C2 C2U2
7 C3 C3U1