Could you help me with the following question: note that this code generates a coefficient from a date and category I have chosen, in this case for 30/06 and FDE category and the coefficient was 4. However, I would like to do a table with the coefficient of all the dates/categories I have, that way I don't need to keep doing one by one.
library(dplyr)
library(tidyverse)
library(lubridate)
df1 <- structure(
list(date1= c("2021-06-28","2021-06-28","2021-06-28","2021-06-28"),
date2 = c("2021-06-30","2021-06-30","2021-07-01","2021-07-01"),
Category = c("FDE","ABC","FDE","ABC"),
Week= c("Wednesday","Wednesday","Friday","Friday"),
DR1 = c(4,1,6,3),
DR01 = c(4,1,4,3), DR02= c(4,2,6,2),DR03= c(9,5,4,7),
DR04 = c(5,4,3,2),DR05 = c(5,4,5,4),
DR06 = c(2,4,3,2),DR07 = c(2,5,4,4),
DR08 = c(3,4,5,4),DR09 = c(2,3,4,4)),
class = "data.frame", row.names = c(NA, -4L))
dmda<-"2021-06-30"
CategoryChosse<- "FDE"
x<-df1 %>% select(starts_with("DR0"))
x<-cbind(df1, setNames(df1$DR1 - x, paste0(names(x), "_PV")))
PV<-select(x, date2,Week, Category, DR1, ends_with("PV"))
med<-PV %>%
group_by(Category,Week) %>%
summarize(across(ends_with("PV"), median))
SPV<-df1%>%
inner_join(med, by = c('Category', 'Week')) %>%
mutate(across(matches("^DR0\\d $"), ~.x
get(paste0(cur_column(), '_PV')),
.names = '{col}_{col}_PV')) %>%
select(date1:Category, DR01_DR01_PV:last_col())
SPV<-data.frame(SPV)
mat1 <- df1 %>%
filter(date2 == dmda, Category == CategoryChosse) %>%
select(starts_with("DR0")) %>%
pivot_longer(cols = everything()) %>%
arrange(desc(row_number())) %>%
mutate(cs = cumsum(value)) %>%
filter(cs == 0) %>%
pull(name)
(dropnames <- paste0(mat1,"_",mat1, "_PV"))
SPV <- SPV %>%
filter(date2 == dmda, Category == CategoryChosse) %>%
select(-any_of(dropnames))
datas<-SPV %>%
filter(date2 == ymd(dmda)) %>%
group_by(Category) %>%
summarize(across(starts_with("DR0"), sum)) %>%
pivot_longer(cols= -Category, names_pattern = "DR0(. )", values_to = "val") %>%
mutate(name = readr::parse_number(name))
colnames(datas)[-1]<-c("Days","Numbers")
datas <- datas %>%
group_by(Category) %>%
slice((as.Date(dmda) - min(as.Date(df1$date1) [
df1$Category == first(Category)])):max(Days) 1) %>%
ungroup
mod <- nls(Numbers ~ b1*Days^2 b2,start = list(b1 = 0,b2 = 0),data = datas, algorithm = "port")
> coef(mod)[2]
b2
4
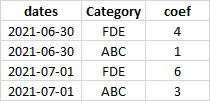
The output of the table will look like this:
CodePudding user response:
Put the code in a function and apply it using mapply -
cbind(df1[2:3], coef = mapply(return_coef, df1$date2, df1$Category))
# date2 Category coef
#1 2021-06-30 FDE 4
#2 2021-06-30 ABC 1
#3 2021-07-01 FDE 6
#4 2021-07-01 ABC 3
where return_coef is -
return_coef <- function(dmda, CategoryChosse) {
x<-df1 %>% select(starts_with("DR0"))
x<-cbind(df1, setNames(df1$DR1 - x, paste0(names(x), "_PV")))
PV<-select(x, date2,Week, Category, DR1, ends_with("PV"))
med<-PV %>%
group_by(Category,Week) %>%
summarize(across(ends_with("PV"), median))
SPV<-df1%>%
inner_join(med, by = c('Category', 'Week')) %>%
mutate(across(matches("^DR0\\d $"), ~.x
get(paste0(cur_column(), '_PV')),
.names = '{col}_{col}_PV')) %>%
select(date1:Category, DR01_DR01_PV:last_col())
SPV<-data.frame(SPV)
mat1 <- df1 %>%
filter(date2 == dmda, Category == CategoryChosse) %>%
select(starts_with("DR0")) %>%
pivot_longer(cols = everything()) %>%
arrange(desc(row_number())) %>%
mutate(cs = cumsum(value)) %>%
filter(cs == 0) %>%
pull(name)
(dropnames <- paste0(mat1,"_",mat1, "_PV"))
SPV <- SPV %>%
filter(date2 == dmda, Category == CategoryChosse) %>%
select(-any_of(dropnames))
datas<-SPV %>%
filter(date2 == ymd(dmda)) %>%
group_by(Category) %>%
summarize(across(starts_with("DR0"), sum)) %>%
pivot_longer(cols= -Category, names_pattern = "DR0(. )", values_to = "val") %>%
mutate(name = readr::parse_number(name))
colnames(datas)[-1]<-c("Days","Numbers")
datas <- datas %>%
group_by(Category) %>%
slice((as.Date(dmda) - min(as.Date(df1$date1) [
df1$Category == first(Category)])):max(Days) 1) %>%
ungroup
mod <- nls(Numbers ~ b1*Days^2 b2,start = list(b1 = 0,b2 = 0),data = datas, algorithm = "port")
as.numeric(coef(mod)[2])
}