I have a text file, 'student.txt'. Some keys have multiple values. I only want data that is tied to the name, and the sibling & hobby values below that name.
'student.txt'
ignore me
name-> Alice
name-> Sam
sibling-> Kate,
unwanted
sibling-> Luke,
hobby_1-> football
hobby_2-> games
name-> Ramsay
hobby_1-> dance
unwanted data
hobby_2-> swimming
hobby_3-> jogging
ignore data
Code I've done:
file = open("student.txt", "r")
with open("student.csv", "w") as writer:
main_dict = {}
student_dict = {"Siblings": "N/A", "Hobbies": "N/A"}
sibling_list = []
hobby_list = []
flag = True
writer.write ('name,siblings,hobbies\n')
header = 'Name,Siblings,Hobbies'.split(',')
sib_str = ''
hob_str =''
for eachline in file:
try:
key, value = eachline.split("-> ")
value = value.strip(",\n")
if flag:
if key == "name":
print (key,value)
if len(sibling_list) > 0:
main_dict[name]["Siblings"] = sib_str
#print (main_dict)
if len(hobby_list) > 0:
main_dict[name]["Hobbies"] = hob_str
sibling_list = []
hobby_list = []
name = value
main_dict[name] = student_dict.copy()
main_dict[name]["Name"] = name
elif key == "sibling":
sibling_list.append(value)
sib_str= ' '.join(sibling_list).replace(' ', '\n')
elif key.startswith("hobby"):
hobby_list.append(value)
hob_str = ' '.join(hobby_list)
if len(sibling_list) > 0:
main_dict[name]["Siblings"] = sib_str
if len(hobby_list) > 0:
main_dict[name]["Hobbies"] = hob_str
if 'name' in eachline:
if 'name' in eachline:
flag = True
else:
flag = False
except:
pass
for eachname in main_dict.keys():
for eachkey in header:
writer.write(str(main_dict[eachname][eachkey]))
writer.write (',')
if 'Hobbies' in eachkey:
writer.write ('\n')
CSV Output from Code above:
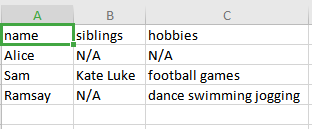
Expected CSV Output:
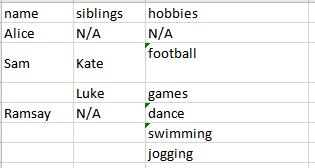
P.S: I can't seem to figure out how to not forgo the try/pass. As some lines (without '->') are unwanted, and I can't use the eachline.split("-> "). Would appreciate help on this too.
Thanks so much!
CodePudding user response:
Please see the code I have pasted below, it gives the csv file which you can import in your excel and it will be in exact format you are expecting.
You can use something like
if "->" not in line:
continue
To skip lines that don't contain "->" values, see in the code below:
import csv
file = open("student.txt", "r")
students = {}
name = ""
for line in file:
if "->" not in line:
continue
line = line.strip(",\n")
line = line.replace(" ", "")
key, value = line.split("->")
if key == "name":
name = value
students[name] = {}
students[name]["siblings"] = []
students[name]["hobbies"] = []
else:
if "sibling" in key:
students[name]["siblings"].append(value)
elif "hobby" in key:
students[name]["hobbies"].append(value)
#print(students)
csvlines = []
for student in students:
name = student
hobbies = students[name]["hobbies"]
siblings = students[name]["siblings"]
maxlength = 0
if len(hobbies) > len(siblings) :
maxlength = len(hobbies)
else:
maxlength = len(siblings)
if maxlength == 0:
csvlines.append([name, "N/A", "N/A"])
continue
for i in range(maxlength):
if i < len(siblings):
siblingvalue = siblings[i]
elif i == len(siblings):
siblingvalue = "N/A"
else:
siblingvalue = ""
if i < len(hobbies):
hobbyvalue = hobbies[i]
elif i == len(siblings):
hobbyvalue = "N/A"
else:
hobbyvalue = ""
if i == 0:
csvlines.append([name, siblingvalue, hobbyvalue])
else:
csvlines.append(["", siblingvalue, hobbyvalue])
print(csvlines)
fields = ["name", "siblings", "hobbies"]
with open("students.csv", 'w') as csvfile:
# creating a csv writer object
csvwriter = csv.writer(csvfile)
# writing the fields
csvwriter.writerow(fields)
# writing the data rows
csvwriter.writerows(csvlines)
If this helped you please do mark it as the answer or leave a comment if you are unclear about something in this. Thanks