I have the DataFrame, where I am trying to add a new "rank" column to determine the price rating relative to the "name" and "country" columns by comparing prices (column 'price'). If one product's price is the same, when using the
df['rank'] = df.groupby('name')['price'].apply(lambda x: x.sort_values().rank())
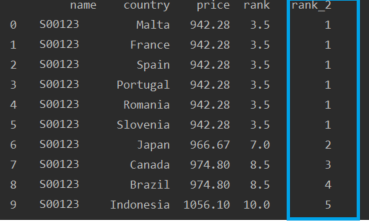
I get the following result -> column 'rank', but I need to get the one that is highlighted in the 'rank_2' and it is not accurate, because these six products have the same price and should get a rating of 1. How is it possible to get the given result as in the column -> 'rank_2'. Help please, I will be grateful
CodePudding user response:
you have to select the method of ranking in the rank function, like so :
df['rank'] = df.groupby('name')['price'].apply(lambda x: x.sort_values().rank(method="dense"))
CodePudding user response:
If I understood you correctly:
You can use:
df['rank'] = df.sort_values(by=['name', 'price']).groupby(['name'])[['price']].apply(lambda x: x!= x.shift()).cumsum()
OR
df['rank'] = df.sort_values(by=['name', 'price']).groupby('name')['price'].apply(lambda x: x.rank(method="dense"))
Output in both cases:
name country price rank
0 S00123 mal 3.5 1.0
1 S00123 fra 3.5 1.0
2 S00123 spa 3.5 1.0
3 S00123 pur 3.5 1.0
4 S00123 rom 3.5 1.0
5 S00123 slo 3.5 1.0
6 S00123 jap 7.0 2.0
7 S00123 can 8.5 3.0
8 S00123 bra 8.5 3.0
9 S00123 ind 10.0 4.0