I have two dataframes shown as below. How can I replace Bank1 data by subtracting 10 by 3, and 55 by 2?
import pandas as pd
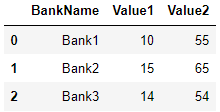
data = [['Bank1', 10, 55], ['Bank2', 15,65], ['Bank3', 14,54]]
df1 = pd.DataFrame(data, columns = ['BankName', 'Value1','Value2'])
df2 = pd.DataFrame([[3, 2]], columns = ['Value1','Value2'])

Desired Output(Only replace values in Bank1):
| BankName | Value1 | Value2 |
|---|---|---|
| Bank1 | 7 | 53 |
| Bank2 | 15 | 65 |
| Bank3 | 14 | 54 |
CodePudding user response:
try, using sub combine_first
df1.sub(df2).combine_first(df1)
BankName Value1 Value2
0 Bank1 7.0 53.0
1 Bank2 15.0 65.0
2 Bank3 14.0 54.0
CodePudding user response:
First solution is create index in df22 by Bankname for align by df1 for correct row subracting:
df.set_index('BankName').sub(df2.set_index([['Bank1']]), fill_value=0)
df.set_index('BankName').sub(df2.set_index([['Bank2']]), fill_value=0)
You need create new column to df2 with BankName, convert BankName to index in both DataFrames, so possible subtract by this row:
df22 = df2.assign(BankName = 'Bank1').set_index('BankName')
df = df1.set_index('BankName').sub(df22, fill_value=0).reset_index()
print (df)
BankName Value1 Value2
0 Bank1 7.0 53.0
1 Bank2 15.0 65.0
2 Bank3 14.0 54.0
Subtract by Bank2:
df22 = df2.assign(BankName = 'Bank2').set_index('BankName')
df = df1.set_index('BankName').sub(df22, fill_value=0).reset_index()
print (df)
BankName Value1 Value2
0 Bank1 10.0 55.0
1 Bank2 12.0 63.0
2 Bank3 14.0 54.0
Another solution with filter by BankName:
m = df1['BankName']=='Bank1'
df1.loc[m, df2.columns] = df1.loc[m, df2.columns].sub(df2.iloc[0])
print (df1)
BankName Value1 Value2
0 Bank1 7 53
1 Bank2 15 65
2 Bank3 14 54
m = df1['BankName']=='Bank2'
df1.loc[m, df2.columns] = df1.loc[m, df2.columns].sub(df2.iloc[0])