Using tabula I read pdf file and got a table:
data = {'country_code': [123, 124, 125, 127, 128, 'city_', 'code', 211, 221, 223, 224, 'store_', 'NA', 'code', 321, 3231, 3213, 32123],
}
what_i_have = pd.DataFrame(data)
what_i_have

There some NaN values(tha't not a problem) and some titles moved down(that is a problem).
I'd like to get something like this: P.S. names of types are not important. I just want to differ codes
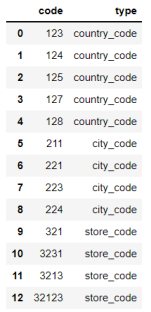
CodePudding user response:
If we need pandas to fix the issue , the idea still be split the word and number into two columns
df.country_code = df.country_code.replace('NA','')
t = pd.to_numeric(df.country_code,errors = 'coerce').isna()
s = df[t].reset_index()
s = s.groupby(s['index'].diff().ne(1).cumsum()).agg({'index':'first','country_code':'sum'}).set_index('index')
df['New'] = s['country_code'].reindex(df.index).ffill().fillna('country_code')
df = df[~t]
country_code New
0 123 country_code
1 124 country_code
2 125 country_code
3 127 country_code
4 128 country_code
7 211 city_code
8 221 city_code
9 223 city_code
10 224 city_code
14 321 store_code
15 3231 store_code
16 3213 store_code
17 32123 store_code
CodePudding user response:
Try:
df = df.dropna()
df["type"] = df.where(df["country_code"].str.contains("_", na=False)).ffill().fillna("country_") "code"
df["country_code"] = pd.to_numeric(df["country_code"], errors="coerce")
df = df.dropna()
>>> df
country_code type
0 123.0 country_code
1 124.0 country_code
2 125.0 country_code
3 127.0 country_code
4 128.0 country_code
7 211.0 city_code
8 221.0 city_code
9 223.0 city_code
10 224.0 city_code
14 321.0 store_code
15 3231.0 store_code
16 3213.0 store_code
17 32123.0 store_code
Input df:
df = pd.DataFrame({'country_code': [123, 124, 125, 127, 128, 'city_', 'code',
211, 221, 223, 224, 'store_', np.nan, 'code',
321, 3231, 3213, 32123]})