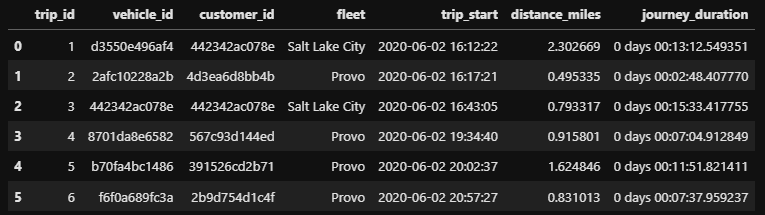
I have taken the following sample of data.
trip_id,vehicle_id,customer_id,fleet,trip_start,distance_miles,journey_duration
1,d3550e496af4,442342ac078e,Salt Lake City,2020-06-02 16:12:22,2.30266927956152,0 days 00:13:12.549351
2,2afc10228a2b,4d3ea6d8bb4b,Provo,2020-06-02 16:17:21,0.495335235709548,0 days 00:02:48.407770
3,442342ac078e,442342ac078e,Salt Lake City,2020-06-02 16:43:05,0.7933172567617909,0 days 00:15:33.417755
4,8701da8e6582,567c93d144ed,Provo,2020-06-02 19:34:40,0.9158009891104686,0 days 00:07:04.912849
5,b70fa4bc1486,391526cd2b71,Provo,2020-06-02 20:02:37,1.6248457639858709,0 days 00:11:51.821411
6,f6f0a689fc3a,2b9d754d1c4f,Provo,2020-06-02 20:57:27,0.8310125874177197,0 days 00:07:37.959237
I read this data into a df using:
df = pd.read_clipboard(sep=',')
What I'm struggling to figure out is how to create a summary table using this information. The output df I would like is below:

Here, I want to group by city, while being able to calculate the total number of unique vehicles, unique customers, trips, and the sum of the total distance and duration (in minutes) of every journey in that city.
For example, we can see that for row 0 and 2, there are 2 unique vehicles but it's from the same customer.
I have tried using groupby/summing/unique methods but have had issues when it comes to certain values I want to obtain. Any idea of where to go next? Cheers
CodePudding user response:
You need to convert a few columns and then you can just group and summarise
df['trip_start'] = pd.to_datetime(df['trip_start'], format='%Y-%d-%m %H:%M:%S')
df['journey_duration'] = pd.to_timedelta(df['journey_duration'])
df['Date'] = df['trip_start'].dt.strftime('%b %Y')
df.groupby(['Date', 'fleet']).agg(
Total_Customers = ('customer_id', 'nunique'),
Total_Vehicles = ('vehicle_id', 'nunique'),
Total_Trips = ('trip_id', 'nunique'),
Total_Distance = ('distance_miles', 'sum'),
Total_Duration = ('journey_duration', 'sum'),
)