With beautifulsoup I have access to the content of this web page: 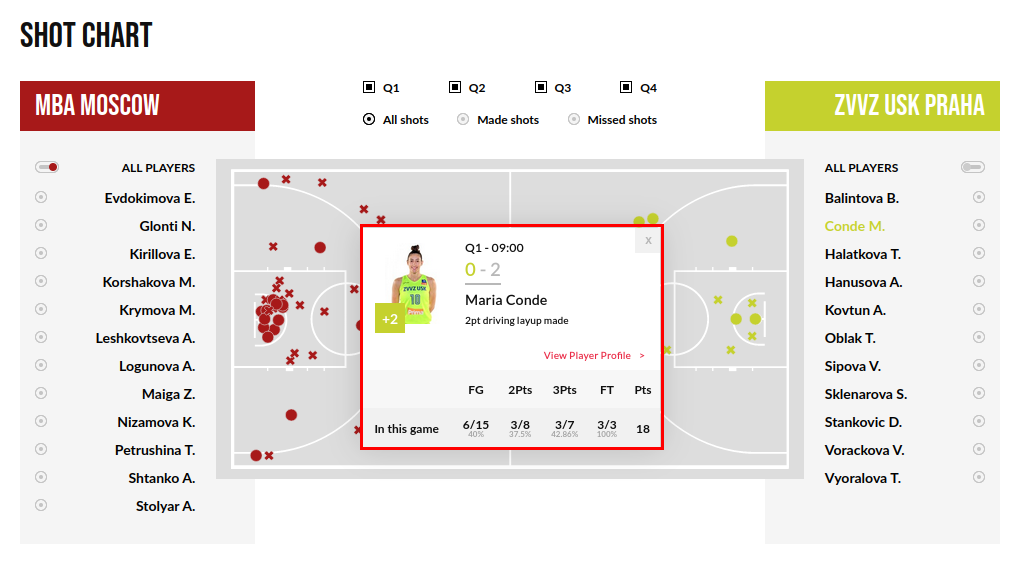
If I inspect this image with Firefox, for example, I've got this code in the console:
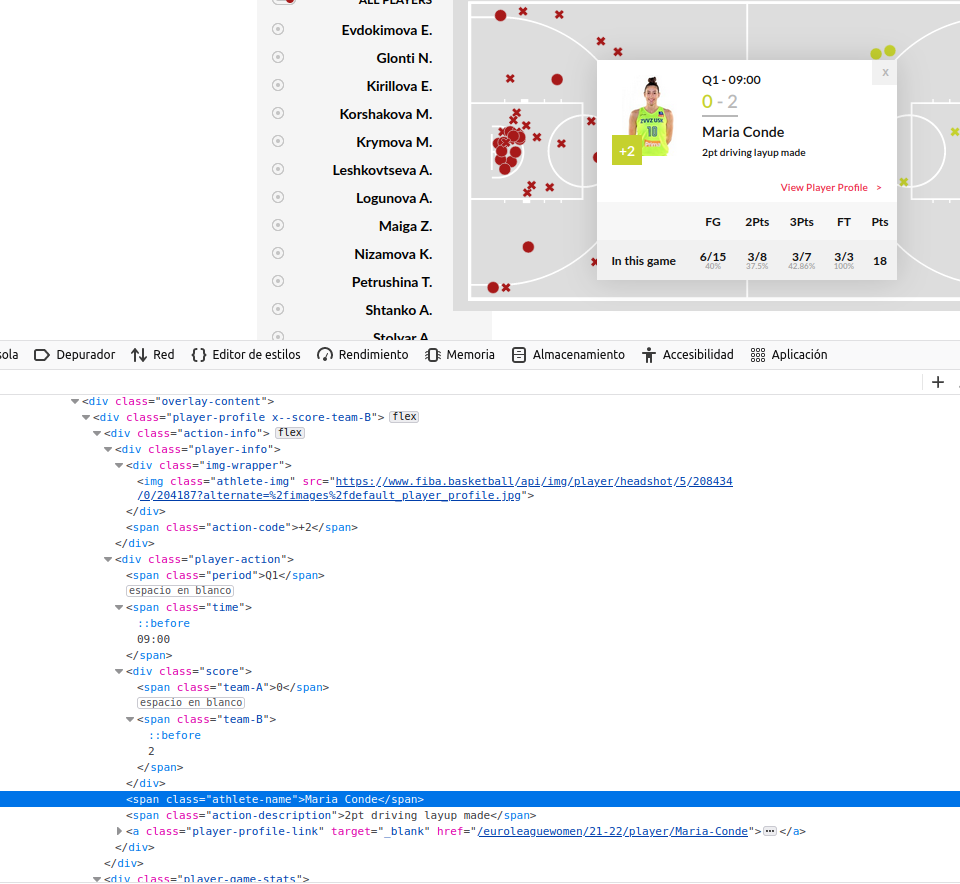
As you can see we've got the information which is showed in the modal window.
Therefore, I would like how to get the URL of this content that appears in the modal window or how to web scrape this content using BeautifulSoup?
CodePudding user response:
The data you see on the page is loaded from external URL. You can use this example to load the data and creating a dataframe with scoring stats:
import re
import json
import requests
import pandas as pd
url = "https://www.fiba.basketball/euroleaguewomen/21-22/game/1310/MBA-Moscow-ZVVZ-USK-Praha#tab=shot_chart"
api_url = "https://livecache.sportresult.com/node/db/FIBASTATS_PROD/{event_id}_GAME_{rsc}_JSON.json?s=unknown&t=0"
html_doc = requests.get(url).text
event_id = re.search(r"setEventId\('(.*?)'\)", html_doc).group(1)
rsc = re.search(r"rsc: '(.*?)'", html_doc).group(1)
data = requests.get(api_url.format(event_id=event_id, rsc=rsc)).json()
# print full data:
# print(json.dumps(data, indent=4))
# print basic table:
df = pd.json_normalize(data["content"]["full"]["ScoreList"]).explode("Items")
df = pd.concat([df, df.pop("Items").apply(pd.Series)], axis=1)
print(df)
Prints:
Period AC C1 Code SA SB Score Team Time
0 Q1 P2 P_204187 2 0 2 0-2 T_65512 09:00
0 Q1 P3 P_151112 5 0 5 0-5 T_65512 07:48
0 Q1 P2 P_174621 7 0 7 0-7 T_65512 06:40
0 Q1 P3 P_204187 10 0 10 0-10 T_65512 06:15
0 Q1 P2 P_174621 12 0 12 0-12 T_65512 05:41
0 Q1 P2 P_160522 10 2 12 2-12 T_9998 03:57
0 Q1 P2 P_195803 8 4 12 4-12 T_9998 03:29
0 Q1 P2 P_204187 10 4 14 4-14 T_65512 02:55
0 Q1 P2 P_174621 12 4 16 4-16 T_65512 01:24
0 Q1 P3 P_137210 9 7 16 7-16 T_9998 00:57
0 Q1 P2 P_160420 11 7 18 7-18 T_65512 00:33
0 Q1 FT P_174621 12 7 19 7-19 T_65512 00:11
1 Q2 P2 P_219548 14 7 21 7-21 T_65512 09:26
1 Q2 P3 P_204187 17 7 24 7-24 T_65512 08:30
1 Q2 P2 P_219548 19 7 26 7-26 T_65512 08:05
...