I'm trying to extract data from this API:https://www.balldontlie.io/#get-all-stats with the following code in python:
import requests
import json
import time
total_results = []
pages_to_read = 11000
counter = 0
for page_num in range(1, pages_to_read 1):
url = "https://balldontlie.io/api/v1/stats?per_page=100&page=" str(page_num)
print("reading", url)
response = requests.get(url)
data = response.json()
total_results = total_results data['data']
counter = counter 1
print(counter)
if counter == 59:
counter = 0
print('break')
time.sleep(60)
print("Total of", len(total_results), "results")
with open('test.json', 'w', encoding='utf-8') as d:
json.dump(total_results, d, ensure_ascii=False, indent=4)
However, I always get this error: https://cdn1.gnarususercontent.com.br/1/292460/5c2858ca-33df-4bd8-9b44-0d50a48ab3e0.png
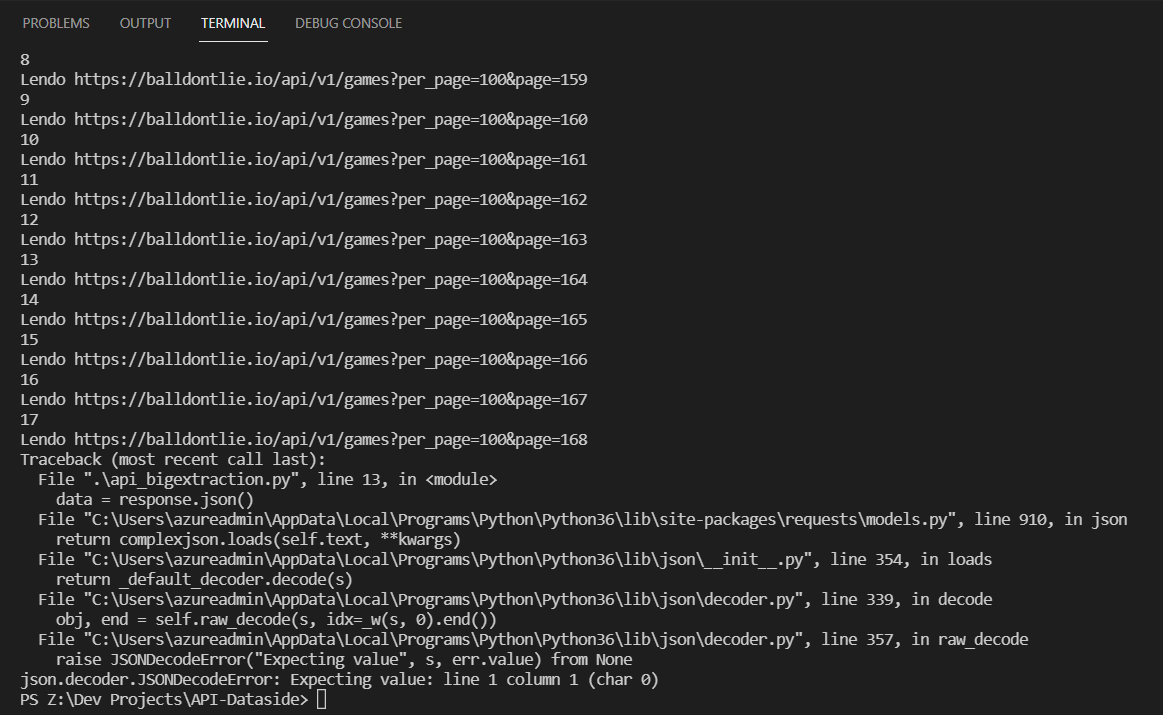{kind=link}
The API should support 60 requests per second, sometimes it even goes beyond 60, but in the end it always gets this error. Does anyone have any suggestions to help me?
PS: I would need data from all 11000 pages of 'stats'. Only the json 'data' data of the page, not counting the 'meta data' and the page number.
CodePudding user response:
Found this answer:
import requests
import json
import time
from datetime import datetime
resultados_totais = []
paginas_totais_para_ler = 11486
def get_api_data(page_num):
url = "https://balldontlie.io/api/v1/stats?per_page=100&page=" str(page_num)
current_time = datetime.now().strftime("%H:%M:%S")
print("{} - Lendo {}".format(current_time, url))
start_request = datetime.now()
response = requests.get(url)
end_request = datetime.now()
delta = end_request - start_request
if delta.seconds <= 0:
time.sleep(1)
if response.status_code == 200:
data = response.json()
response.raise_for_status()
return data['data']
else:
current_time = datetime.now().strftime("%H:%M:%S")
print("{} - ({}) Limite de request ... aguardando 15 seg para tentar novamente".format(current_time, response.status_code))
time.sleep(15)
return get_api_data(page_num)
for page_num in range(1, paginas_totais_para_ler 1):
resultados_totais.extend(get_api_data(page_num))
if page_num == paginas_totais_para_ler:
print('\nSalvando Arquivo json..')
with open('all_stats.json', 'w', encoding='utf-8') as d:
json.dump(resultados_totais, d, ensure_ascii=False, indent=4)
print('\nArquivo Salvo!!')
print("\nTemos um total de", len(resultados_totais), "resultados.")