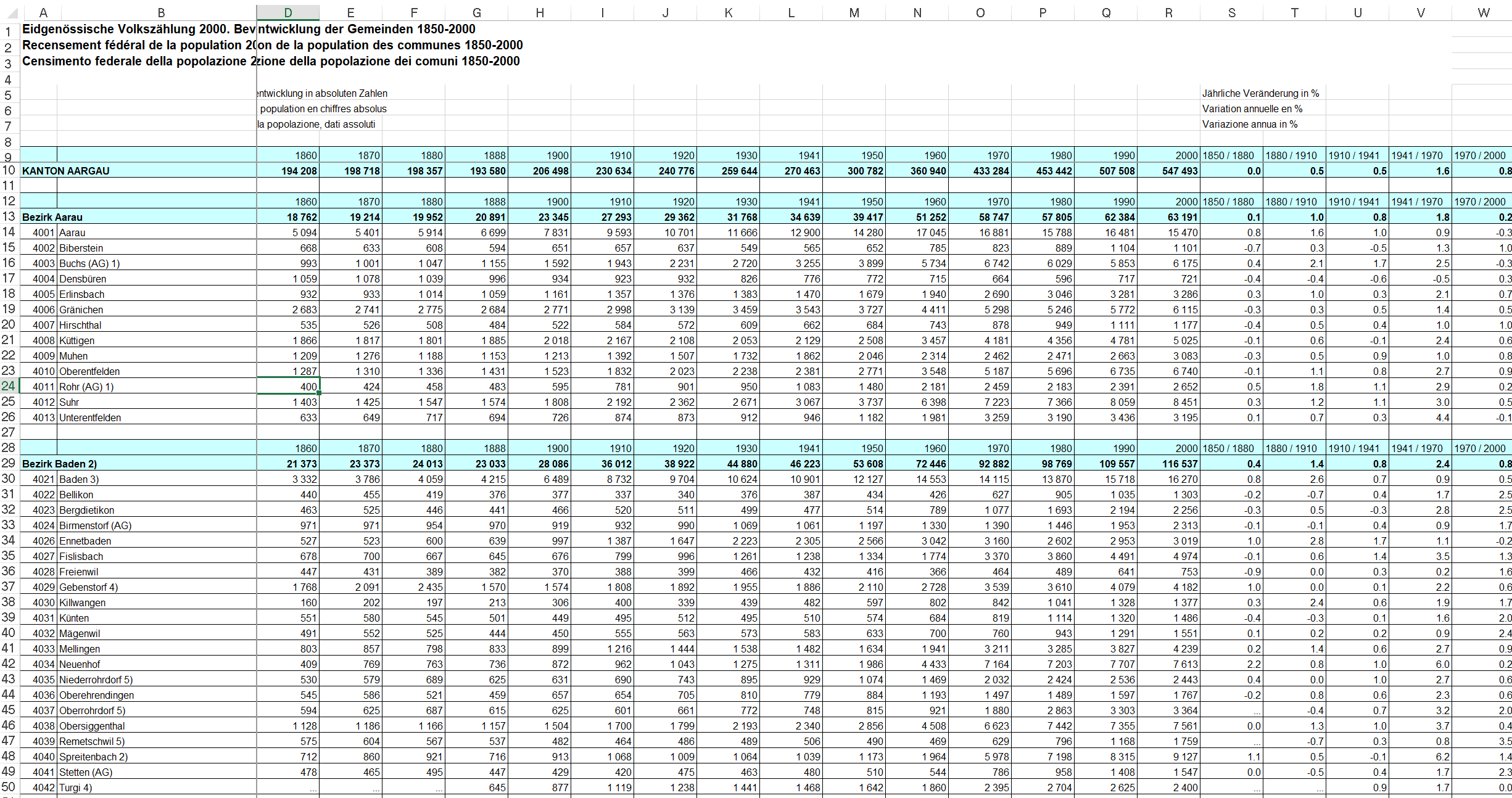
I am working on a couple of excel sheets which all look like the first one attached. Currently I'm trying to remove the first 11 rows, and also the first column based on the index. Somehow I can not get it to work, The title "Eidgenössische Volkszählung 2000. Bevölkerungsentwicklung der Gemeinden 1850-2000" is still visible. It removes all the rows without the Title.
My end goal would be to make it look like the second picture, shouldnt be that hard i think.
If someone could tell me how to remove rows and colums based on the index i would be grateful. I did not find any solution within my 1h google search.
import pandas as pd
df = pd.read_excel("AG.xls", "AG")
df = df.drop([0,1,2,3,4,5,6,7,8,9,10])
print(df)

CodePudding user response:
Try:
import pathlib
data_dir = pathlib.Path('.')
data = []
for xlsfile in data_dir.glob('??.xls'):
df = pd.read_excel(xlsfile, skiprows=8)
df = df[pd.to_numeric(df.iloc[:, 0], errors='coerce').notna()]
df = pd.concat([df.iloc[:, 1:].set_index('Unnamed: 1')],
keys=[xlsfile.stem], names=['Kanton', 'Stadt'])
data.append(df)
df = pd.concat(data)
Rows are filtered with the first column. If the column Unnamed: 0 can be converted to numeric then keep it else drop. I use skiprows=8 to get the column headers (1850, 1860, ...). The index of each dataframe is a MultiIndex: the filename name - Kanton - (xlsfile.stem) and the city - Stadt - (column Unnamed: 1).
Output result:
>>> df
1850 1860 1870 1880 1888 1900 1910 1920 1930 1941 1950 1960 1970 1980 1990 2000 1850 / 1880 1880 / 1910 1910 / 1941 1941 / 1970 1970 / 2000
Kanton Stadt
TI Arbedo-Castione 801 773 800 839 873 1042 1200 1212 1260 1302 1335 1467 2456 3058 3570 3729 0.2 1.2 0.3 2.2 1.4
Bellinzona 1) 3209 3462 3950 4038 5553 8255 10406 10232 10706 10948 12060 13435 16979 16743 16849 16463 0.8 3.2 0.2 1.5 -0.1
Cadenazzo 216 229 231 538 316 333 408 481 482 505 621 693 995 1179 1500 1755 3.1 -0.9 0.7 2.4 1.9
Camorino 321 337 467 483 423 405 491 571 548 552 702 920 1376 1476 1709 2210 1.4 0.1 0.4 3.2 1.6
Giubiasco 2) 1417 1503 1539 1587 1570 1722 2395 2585 2607 2932 3311 4281 5796 6585 6982 7418 0.4 1.4 0.7 2.4 0.8
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
ZG Risch 1005.0 1027.0 896.0 1235.0 1171.0 1047.0 1106.0 1258.0 1281.0 1449.0 1630.0 2038.0 3182.0 3988.0 5414.0 7241.0 0.7 -0.4 0.9 2.7 2.8
Steinhausen 490.0 465.0 436.0 468.0 498.0 443.0 470.0 560.0 743.0 787.0 1078.0 1621.0 4138.0 6082.0 7207.0 8801.0 -0.2 0.0 1.7 5.9 2.5
Unterägeri 2243.0 2423.0 2565.0 2426.0 2378.0 2593.0 2502.0 2787.0 3005.0 2969.0 3340.0 3832.0 4671.0 5371.0 6151.0 7179.0 0.3 0.1 0.6 1.6 1.4
Walchwil 1039.0 1030.0 1072.0 1054.0 1021.0 1059.0 1043.0 1046.0 1072.0 1118.0 1226.0 1400.0 1675.0 2181.0 2654.0 3150.0 0.0 0.0 0.2 1.4 2.1
Zug 1) 3302.0 3854.0 4243.0 4805.0 5120.0 6508.0 8096.0 9499.0 11113.0 12372.0 14488.0 19792.0 22972.0 21609.0 21705.0 22973.0 1.3 1.8 1.4 2.2 0.0
[2896 rows x 21 columns]
CodePudding user response:
Try this one
Option 1: dropping the rows and column while reading
df = pd.read_excel('AG.xlsx', skiprows=list(range(10))).drop('Unnamed: 0', axis=1)
To skip rows, you can use skiprows argument for read_excel, 