New coder here. I've been trying to scrape just one piece of text on a very java based website for a while now using Selenium. Not sure what I am doing wrong that this point.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://explorer.helium.com/accounts/13pm9juR7WPjAf7EVWgq5EQAaRTppu2EE7ReuEL9jpkHQMJCjn9")
earnings = driver.find_elements_by_class_name('text-base text-gray-600 mb-1 tracking-tight w-full break-all')
print(earnings)
driver.quit()
Image of attempted element to scrape :
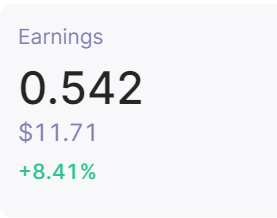
I am trying to scrape that dollar amount in this container so I can eventually use it in a daily report that I am building.
Everything I have tried has resulted in it returning none. Even when I try to grab the text from that element.
Here is website link: https://explorer.helium.com/accounts/13pm9juR7WPjAf7EVWgq5EQAaRTppu2EE7ReuEL9jpkHQMJCjn9
CodePudding user response:
You should wait until javascript loads, page loads, elements loads.
_ = driver.Manage().Timeouts().ImplicitWait;
You can create condition until element appers.
ExpectedConditions ...... define selenium conditions
//This is how we specify the condition to wait on.
wait.until(ExpectedConditions.alertIsPresent());
You can use XPATH ! The DOLLAR XPATH IS
/html/body/div[1]/div/article/div[2]/div/div[2]/div/div[2]/div[1]/div[2]/div[2]
FIREFOX XPATH FINDER
https://addons.mozilla.org/en-US/firefox/addon/xpath_finder/
CodePudding user response:
You can use this xpath
//*[@id="app"]/article/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div[1]/div[3]