I want to find the unique count and null percent for all columns in a mysql database for the purpose of data discovery(tables with approximation of null/distinct is also fine). Postgres has the pg_stats table with the null_frac and n_distinct fields, is there a table containing similar stats in mysql? Not looking to run this query through all the columns.
SELECT COUNT( DISTINCT col1) FROM table1;
Here is a sample data:
CREATE TABLE employees (
employeeNumber INT NOT NULL,
lastName VARCHAR(50) NOT NULL,
firstName VARCHAR(50) NOT NULL,
extension VARCHAR(10) NOT NULL,
email VARCHAR(100) NOT NULL,
officeCode VARCHAR(10) NOT NULL,
reportsTo INT DEFAULT NULL,
jobTitle VARCHAR(50) NOT NULL,
PRIMARY KEY (employeeNumber)
) ;
INSERT INTO employees(employeeNumber,lastName,firstName,extension,email,officeCode,reportsTo,jobTitle) VALUES
(1002,'Murphy','Diane','x5800','[email protected]','1',NULL,'President'),
(1056,'Patterson','Mary','x4611','[email protected]','1',1002,'VP Sales'),
(1076,'Firrelli','Jeff','x9273','[email protected]','1',1002,'VP Marketing'),
(1088,'Patterson','William','x4871','[email protected]','6',1056,'Sales Manager (APAC)'),
(1102,'Bondur','Gerard','x5408','[email protected]','4',1056,'Sale Manager (EMEA)'),
(1143,'Bow','Anthony','x5428','[email protected]','1',1056,'Sales Manager (NA)'),
(1165,'Jennings','Leslie','x3291','[email protected]','1',1143,'Sales Rep'),
(1166,'Thompson','Leslie','x4065','[email protected]','1',1143,'Sales Rep'),
(1188,'Firrelli','Julie','x2173','[email protected]','2',1143,'Sales Rep'),
(1216,'Patterson','Steve','x4334','[email protected]','2',1143,'Sales Rep'),
(1286,'Tseng','Foon Yue','x2248','[email protected]','3',1143,'Sales Rep'),
(1323,'Vanauf','George','x4102','[email protected]','3',1143,'Sales Rep'),
(1337,'Bondur','Loui','x6493','[email protected]','4',1102,'Sales Rep'),
(1370,'Hernandez','Gerard','x2028','[email protected]','4',1102,'Sales Rep'),
(1401,'Castillo','Pamela','x2759','[email protected]','4',1102,'Sales Rep'),
(1501,'Bott','Larry','x2311','[email protected]','7',1102,'Sales Rep'),
(1504,'Jones','Barry','x102','[email protected]','7',1102,'Sales Rep'),
(1611,'Fixter','Andy','x101','[email protected]','6',1088,'Sales Rep'),
(1612,'Marsh','Peter','x102','[email protected]','6',1088,'Sales Rep'),
(1619,'King','Tom','x103','[email protected]','6',1088,'Sales Rep'),
(1621,'Nishi','Mami','x101','[email protected]','5',1056,'Sales Rep'),
(1625,'Kato','Yoshimi','x102','[email protected]','5',1621,'Sales Rep'),
(1702,'Gerard','Martin','x2312','[email protected]','4',1102,'Sales Rep');
This the expected output able to get from postgres using the pg_stats table(specifically the num_null and num_of_distinct columns)
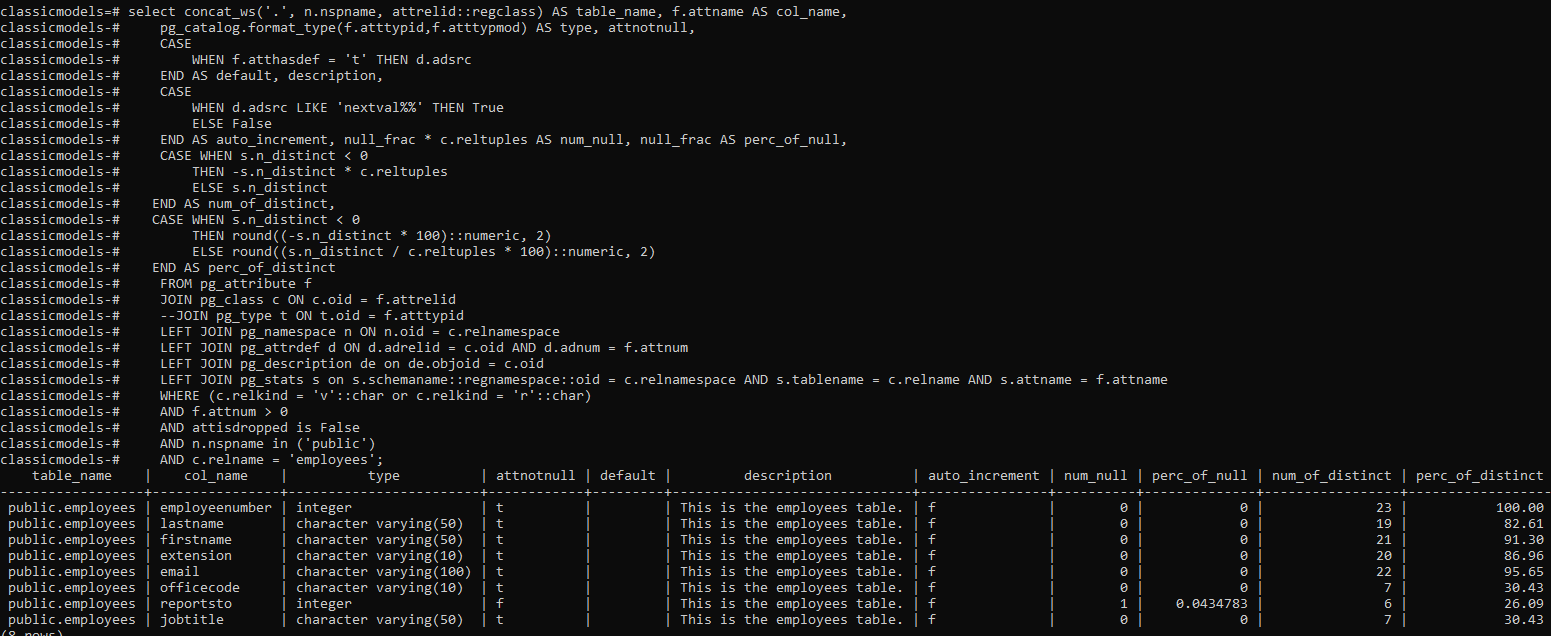 Sample table structure and data in postgres: https://pastebin.com/fXg3RJdi
Sample table structure and data in postgres: https://pastebin.com/fXg3RJdi
Thanks a lot in advance!
CodePudding user response:
This idea is using prepared statement.
- Setting up base query:
SET @sql1 := (SELECT GROUP_CONCAT(CONCAT('SELECT "',column_name,'" AS column_name,
COUNT(DISTINCT ',column_name,') AS num_of_distinct,
SUM(CASE WHEN ',column_name,' IS NULL THEN 1 ELSE 0 END) AS num_null,
COUNT(*) AS TotalRows
FROM employees ') SEPARATOR '
UNION ALL
')
FROM information_schema.COLUMNS
WHERE table_name='employees'
AND table_schema= 'public');
/*Check @sql1 variable*/
SELECT @sql1;
- Setting up outer query with percentage calculation:
SET @sql2 := CONCAT('SELECT *, CAST(num_null/TotalRows AS DECIMAL(14,7)) perc_of_null,
ROUND((num_of_distinct/TotalRows)*100,2) perc_of_distinct
FROM (',@sql1,') tv;');
/*Check @sql2 variable*/
SELECT @sql2;
- Preparing statement from
@sql2variable, execute then deallocate it:
PREPARE stmt FROM @sql2;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
Result:
| column_name | num_of_distinct | num_null | TotalRows | perc_of_null | perc_of_distinct |
|---|---|---|---|---|---|
| employeeNumber | 23 | 0 | 23 | 0.0000000 | 100.00 |
| lastName | 19 | 0 | 23 | 0.0000000 | 82.61 |
| firstName | 21 | 0 | 23 | 0.0000000 | 91.30 |
| extension | 20 | 0 | 23 | 0.0000000 | 86.96 |
| 22 | 0 | 23 | 0.0000000 | 95.65 | |
| officeCode | 7 | 0 | 23 | 0.0000000 | 30.43 |
| reportsTo | 6 | 1 | 23 | 0.0434783 | 26.09 |
| jobTitle | 7 | 0 | 23 | 0.0000000 | 30.43 |
Here's a demo fiddle.
For the full result that is according to your screenshot, you probably can modify the @sql2 variable as following:
SET @sql2 := CONCAT('SELECT CONCAT(tt.table_schema,".",tt.table_name),
cc.COLUMN_NAME,
cc.COLUMN_TYPE,
cc.IS_NULLABLE,
cc.COLUMN_KEY,
tt.TABLE_COMMENT,
cc.EXTRA,
num_of_distinct,
num_null,
num_null/TotalRows perc_of_null, ROUND((num_of_distinct/TotalRows)*100,2) perc_of_distinct
FROM information_schema.COLUMNS cc
JOIN information_schema.TABLES tt ON cc.TABLE_SCHEMA=tt.TABLE_SCHEMA AND cc.TABLE_NAME=tt.TABLE_NAME
JOIN (',@sql1,') tv ON cc.COLUMN_NAME=tv.column_name
WHERE tt.table_schema="Public" AND tt.table_name="employees";');
However, I'm not entirely sure if the table attributes on MySQL matches the ones from Postgres.
CodePudding user response:
You can create your own procedure that will build such a report using prepared statements.
DELIMITER //
CREATE PROCEDURE sys_column_stats (IN tableName varchar(64))
BEGIN
SET SESSION group_concat_max_len = 1000000;
SELECT
GROUP_CONCAT(
'SELECT \'', c.column_name,'\' AS column_name,',
'(SELECT COUNT(DISTINCT `', c.column_name,'`) FROM `', table_name, '`) AS distinct_count,',
'(SELECT SUM(`', c.column_name,'` IS NULL) FROM `', table_name, '`) AS null_count'
-- ... More stats you need
SEPARATOR ' UNION ALL '
) AS sql_statement
INTO @sql
FROM information_schema.columns c
WHERE `table_name` = tableName;
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END//
DELIMITER ;
Usage:
CALL sys_column_stats('employees');
The SQL statement in the procedure prepares the UNION ALL query as
SELECT
'email' AS column_name,
(SELECT COUNT(DISTINCT `email`) FROM `employees`) AS distinct_count,
(SELECT SUM(`email` IS NULL) FROM `employees`) AS null_count
UNION ALL
SELECT
'employeeNumber' AS column_name,
(SELECT COUNT(DISTINCT `employeeNumber`) FROM `employees`) AS distinct_count,
(SELECT SUM(`employeeNumber` IS NULL)FROM `employees`) AS null_count
UNION ALL
[ ... ]