I have 118 CSVs, I need to go into each CSV and change F1, F2, F3 and so on to 0.
For example, in csv1, F1 = 0, in csv2, F2 = 0, in csv3, F3 = 0 and so on.
The CSV has headers:
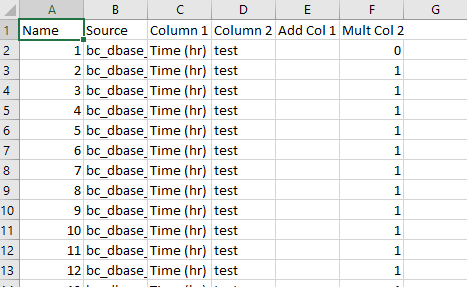
CodePudding user response:
I am assuming all of your CSV files have the same format, and that you are trying to set column F to be 0 for all of them.
You can use Python CSV library to help you as follows:
import csv
import glob
for filename in glob.glob('*.csv'):
print(f'Processing: {filename}')
with open(filename) as f_input:
csv_input = csv.reader(f_input)
header = next(csv_input)
rows = [[*row[:5], '0'] for row in csv_input]
with open(filename, 'w', newline='') as f_output:
csv_output = csv.writer(f_output)
csv_output.writerow(header)
csv_output.writerows(rows)
This reads all .csv files from a given folder and changes the Multi Col 2 values to 0. It does this for all rows but leaves the header the same.
CodePudding user response:
Thank you all, I made my own solution, it is a lot less classy than the ones posted here. But I automated it from the point of needing x number of files to amending the col/row.
#==============================================================================
# Import the necessary packages
import os
#import glob
import shutil
import pathlib
import pandas as pd
#import numpy as np
#==============================================================================
InputPath = 'F:\\cells\\bc_dbase\\bc_dbase1.csv'
OutputPath = 'F:\\cells\\bc_dbase'
str1 = 'Name '
str2 = 'Mult Col 2'
NoStart = 1
NoEnd = 119
#==============================================================================
# Create complete path of folders
def CreatePath(FullPath,File=False):
Parts = pathlib.Path(FullPath).parts
for [n1,Folder] in enumerate(Parts):
if File==True and n1==len(Parts)-1 and "." in Parts[n1]:
continue
elif n1==0:
FolderPath = Parts[n1]
else:
FolderPath = os.path.join(FolderPath,Folder)
if os.path.exists(FolderPath)==False:
os.mkdir(FolderPath)
#==============================================================================
# Delete folder
def DeleteFolder(FullPath):
FullPath = pathlib.Path(FullPath)
try:
shutil.rmtree(FullPath)
except:
pass
#==============================================================================
CreatePath(OutputPath,File=False)
[FolderPath,File] = os.path.split(InputPath)
[FileName,FileExt] = os.path.splitext(os.path.basename(InputPath))
ReversedFileName = FileName[::-1]
AdjFileName = FileName
for n1 in reversed(range(len(AdjFileName))):
char = FileName[n1]
if char.isdigit():
AdjFileName = AdjFileName[:n1] AdjFileName[(n1 1):]
else: break;
Data1 = pd.read_csv(InputPath)
Data2 = pd.DataFrame.copy(Data1)
NameCols = Data1.columns
if str2 in NameCols:
Data2.loc[:,str2] = 1
for n1 in range(NoStart,NoEnd 1):
NewFile = AdjFileName str(n1) FileExt
NewFilePath = os.path.join(OutputPath,NewFile)
Data3 = pd.DataFrame.copy(Data2)
index = Data3[Data3[str1]==n1].index[0]
Data3.loc[index,str2] = 0
Data3.to_csv(NewFilePath, index=False)
print('[INFO] Storing file:',NewFilePath)
#==============================================================================
CodePudding user response:
Mr. Evans has pretty neat code using Python CSV library, so I will expand on it a bit to answer your specific question.
import csv
import glob
file_count = 0
for filename in glob.glob('*.csv'):
file_count = 1
print(f'Processing: {filename}')
with open(filename) as f_input:
csv_input = csv.reader(f_input)
header = next(csv_input)
line_count = 0
rows = []
for row in csv_input:
line_count = 1
if line_count == file_count:
rows.append([*row[:5], '0'])
else:
rows.append([*row[:6]])
with open(filename, 'w', newline='') as f_output:
csv_output = csv.writer(f_output)
csv_output.writerow(header)
csv_output.writerows(rows)
Note: the code will run for all the .csv files in the working directory and will run through the files in an alphabetic order.