I have CSV with 10 columns, one of which is an XML field. When I read this into a databricks notebook from azure data lake it splits up the xml into new rows, instead of keeping it in the one field.
Is there a way to stop this happening? The data looks like this when displayed
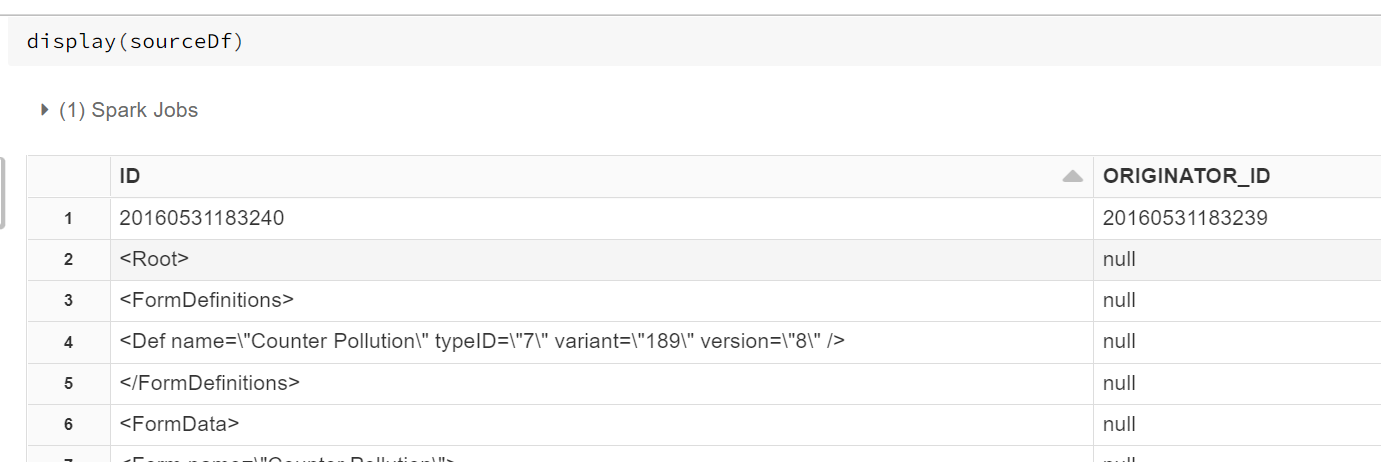
But like this when I open the CSV
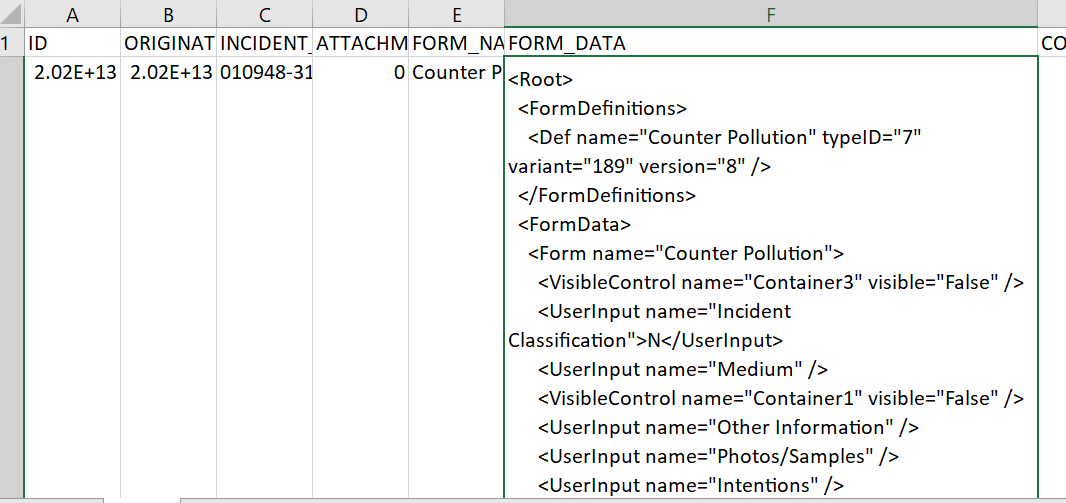
I'm using the following code to read the csv
sourceDf = spark.read.csv(sourceFilePath, sep=',', header=True, inferSchema=True)
I'm attempting to build a data pipeline in ADF and want to use databricks to parse the XML field, but I need to be able to read it in to databricks first.
CodePudding user response:
To read the data correctly I needed to define multiline=True as an option as below:
sourceDf = spark.read.csv(sourceFilePath, sep=',', header=True, inferSchema=True, multiLine=True)
Then I get a correctly formatted column.