I have a dataframe of drug IDs (NDC_NBR) and their corresponding drug names (BRAND_NM).
I need to collapse/aggregate the drug names to the least specificity as possible per drug.
Here is an example of the data I am working with and the expected outcome:
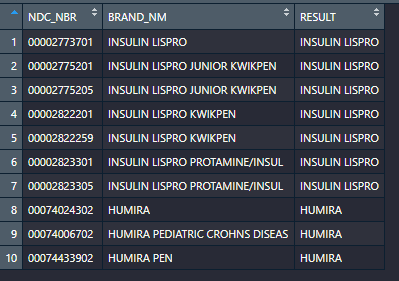
data <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201","00002822259","00002823301","00002823305","00074024302","00074006702","00074433902"),BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL","INSULIN LISPRO PROTAMINE/INSUL","HUMIRA","HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"), RESULT = c("INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","INSULIN LISPRO","HUMIRA","HUMIRA","HUMIRA"))
I wish to collapse these products to the least specific drug names i.e. mutate a new column with the character "INSULIN LISPRO" and "HUMIRA".
"INSULIN LISPRO" is common to the first 7 rows yet "INSULIN LISPRO KWIKPEN" is only common to 2 of the 7. Similarly HUMIRA has no similarity to any of the "INSULIN" rows but is common to all of the last 3 rows.
I have a huge data frame of such products and it's not possible to manually convert each one.
I'd be very grateful if anyone could suggest a solution to such a problem.
CodePudding user response:
Two solutions, each for a different sceanario:
- Scenario # 1 - you have a list of ideal brand names:
Here's a two-step solution for this scenario:
First, define the short brand names as an alternation pattern p:
p <- paste0(BRAND_NM_short, collapse = "|")
Then use this pattern for gsub to match the part in BRAND_NM you want to keep and replace BRAND_NM with just that matched short brand name:
library(dplyr)
data %>%
mutate(result = gsub(paste0("(", p, ").*"), "\\1", BRAND_NM))
NDC_NBR BRAND_NM result
1 00002773701 INSULIN LISPRO INSULIN LISPRO
2 00002775201 INSULIN LISPRO JUNIOR KWIKPEN INSULIN LISPRO
3 00002775205 INSULIN LISPRO JUNIOR KWIKPEN INSULIN LISPRO
4 00002822201 INSULIN LISPRO KWIKPEN INSULIN LISPRO
5 00002822259 INSULIN LISPRO KWIKPEN INSULIN LISPRO
6 00002823301 INSULIN LISPRO PROTAMINE/INSUL INSULIN LISPRO
7 00002823305 INSULIN LISPRO PROTAMINE/INSUL INSULIN LISPRO
8 00074024302 HUMIRA HUMIRA
9 00074006702 HUMIRA PEDIATRIC CROHNS DISEAS HUMIRA
10 00074433902 HUMIRA PEN HUMIRA
- Scenario #2: You don't have a list of the ideal brand names.
Here's a somewhat more complex solution to this problem:
Step 1: Run a for loop to detect any repeated words from one row to the next based on a dynamic pattern:
# initialize vectors/columns:
p1 <- c()
data$repeats <- NA
# for loop to detect repeated words across rows:
library(stringr)
for(i in 2:nrow(data)){
p1[i-1] <- paste0(unlist(str_split(trimws(data$BRAND_NM[i-1]), "\\s ")), collapse = "|")
data$repeats[i] <- str_extract_all(data$BRAND_NM[i], p1[i-1])
}
Step 2: mutate the repeated words to obtain the ideal brand names, assuming that they will maximally contain two words:
data %>%
mutate(result = sapply(repeats, function(x) paste(x[1], x[2], collapse = " ")),
result = sub("\\sNA", "", result),
result = ifelse(grepl("NA", result), lead(result), result)) %>%
select(-repeats)
Data:
BRAND_NM_short = c("INSULIN LISPRO", "HUMIRA")
data <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201","00002822259","00002823301","00002823305","00074024302","00074006702","00074433902"),
BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL","INSULIN LISPRO PROTAMINE/INSUL","HUMIRA","HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"))
CodePudding user response:
here's one way to do it, assuming the first word is always part of the name:
mydata <- data.frame(NDC_NBR = c("00002773701","00002775201","00002775205","00002822201",
"00002822259","00002823301","00002823305","00074024302",
"00074006702","00074433902"),
BRAND_NM = c("INSULIN LISPRO","INSULIN LISPRO JUNIOR KWIKPEN",
"INSULIN LISPRO JUNIOR KWIKPEN","INSULIN LISPRO KWIKPEN",
"INSULIN LISPRO KWIKPEN","INSULIN LISPRO PROTAMINE/INSUL",
"INSULIN LISPRO PROTAMINE/INSUL","HUMIRA",
"HUMIRA PEDIATRIC CROHNS DISEAS","HUMIRA PEN"))
# add the first word as a main grouping column
mydata["main_group"] <- mydata %>% apply(1, function(x) strsplit(x["BRAND_NM"], " ")[[1]][1])
mydata["RESULT"] <- mydata %>%
# per group: get the number of words in common between all rows in group
group_by(main_group) %>%
mutate(intersect_cnt = Reduce(intersect, strsplit(BRAND_NM," ")) %>% length()) %>%
# extract the identified words
apply(1, function(x) paste(strsplit(x["BRAND_NM"], " ")[[1]][1:x["intersect_cnt"]], collapse = " "))
output:
mydata
# NDC_NBR BRAND_NM main_group RESULT
# 1 00002773701 INSULIN LISPRO INSULIN INSULIN LISPRO
# 2 00002775201 INSULIN LISPRO JUNIOR KWIKPEN INSULIN INSULIN LISPRO
# 3 00002775205 INSULIN LISPRO JUNIOR KWIKPEN INSULIN INSULIN LISPRO
# 4 00002822201 INSULIN LISPRO KWIKPEN INSULIN INSULIN LISPRO
# 5 00002822259 INSULIN LISPRO KWIKPEN INSULIN INSULIN LISPRO
# 6 00002823301 INSULIN LISPRO PROTAMINE/INSUL INSULIN INSULIN LISPRO
# 7 00002823305 INSULIN LISPRO PROTAMINE/INSUL INSULIN INSULIN LISPRO
# 8 00074024302 HUMIRA HUMIRA HUMIRA
# 9 00074006702 HUMIRA PEDIATRIC CROHNS DISEAS HUMIRA HUMIRA
# 10 00074433902 HUMIRA PEN HUMIRA HUMIRA