I have a system with two processes, where:
- a 'reader' process, getting frames from a remote camera through RTSP;
- frames read from 'reader' are sent to 'consumer', to run some computer vision algorithms on them.
Now, the problem is that frames are read from the camera in 'reader' at 25 FPS, but they are clearly analyzed much slower in 'consumer'. Then, I don't want 'consumer' to analyze all of them, but only the latest available one (so computer vision detections refer to the live stream).
Something like described here:
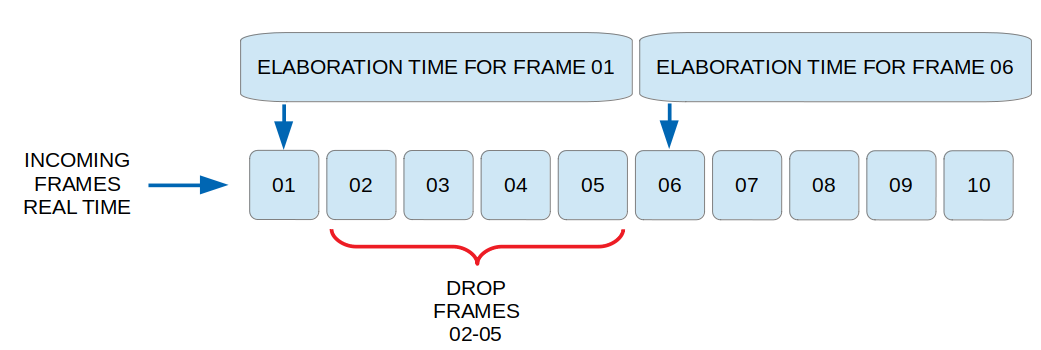
I managed to make this work the way I want by a workaround.
Basically, in reader, I check if the queue is empty. If not, it means the frame there has not been analyzed yet, so I delete it and replace it with the current one used:
launcher.py -> start everything
from reader import Reader
from consumer import Consumer
import multiprocessing as mp
from multiprocessing import set_start_method, Queue, Event
def main():
set_start_method("spawn")
frames_queue = mp.Queue()
stop_switch = mp.Event()
reader = mp.Process(target=Reader, args=(frames_list,), daemon=True)
consumer = mp.Process(target=Consumer, args=(frames_list, stop_switch), daemon=True)
reader.start()
consumer.start()
while True:
if stop_switch.is_set():
reader.terminate()
consumer.terminate()
sys.exit(0)
if __name__ == "__main__":
main()
reader.py -> reading frames from camera
import cv2
def Reader(thing):
cap = cv2.VideoCapture('rtsp_address')
while True:
ret, frame = cap.read()
if ret:
if not frames_queue.empty():
try:
frames_queue.get_nowait() # discard previous (unprocessed) frame
except queue.Empty:
pass
try:
frames_queue.put(cv2.resize(frame, (1080, 720)), block=False)
except:
pass
And something similar in consumer:
consumer.py
import cv2
def Consumer(frames_queue, stop_switch):
while True:
try:
frame = frames_queue.get_nowait() ## get current camera frame from queue
except:
pass
if frame:
## do something computationally intensive on frame
cv2.imshow('output', cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
## stop system when pressing 'q' key
key = cv2.waitKey(1)
if key==ord('q'):
stop_switch.set()
break
But I don't really like this, it seems a little too messy. Also, I have to use all the try/except blocks to avoid racing conditions, where 'reader' empties the queue before putting the new frame, and 'consumer' tries to get a frame at the same time. Any other better way to do this?
CodePudding user response:
A few comments:
According to the documentation on the
multiprocessing.Queue.emptymethod, this is not reliable and should not be used.As I previously commented in a previous post of yours, looping on
get_nowait()calls as you are doing in consumer.py when you should be willing to block until a frame is available is just wasting CPU cycles.Likewise looping in your main process testing
stop_switch.is_set()when you could just be issuingstop_switch.wait()is just wasting CPU cycles.In your main process when you detect that the
stop_switchhas been set, there is no need to explicitly terminate the daemon processes you created; they will terminate automatically when the main process terminates.
Otherwise, cleaning up the above mentioned items should result in code that I don't think is all that messy.
main.py
from reader import Reader
from consumer import Consumer
import multiprocessing as mp
from multiprocessing import set_start_method, Queue, Event
def main():
set_start_method("spawn")
frames_queue = mp.Queue()
stop_switch = mp.Event()
reader = mp.Process(target=Reader, args=(frames_list,), daemon=True)
consumer = mp.Process(target=Consumer, args=(frames_list, stop_switch), daemon=True)
reader.start()
consumer.start()
stop_switch.wait()
if __name__ == "__main__":
main()
reader.py
import cv2
def Reader(thing):
cap = cv2.VideoCapture('rtsp_address')
while True:
ret, frame = cap.read()
if ret:
try:
# discard possible previous (unprocessed) frame
frames_queue.get_nowait()
except queue.Empty:
pass
try:
frames_queue.put(cv2.resize(frame, (1080, 720)), block=False)
except:
pass
consumer.py
import cv2
def Consumer(frames_queue, stop_switch):
while True:
frame = frames_queue.get() ## get current camera frame from queue
## do something computationally intensive on frame
cv2.imshow('output', cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
## stop system when pressing 'q' key
key = cv2.waitKey(1)
if key==ord('q'):
stop_switch.set()
break
CodePudding user response:
Here's some ideas that I can think of...
...I'm not what I'd call an MP expert, but I have used MP and MT a lot in production code for parallel type image processing.
- First question after thinking about what you've said - Why are you using multiprocessing to begin with?
Let me explain this: your highest level problem could be stated as
- "do something computationally intensive on the most recent frame"
- caveat: the time taken for this "something" is much greater than the time to generate a frame.
In your current code you're simply discarding anything but the most recent frame in the producer, and as you state, generating the frames is much faster than processing them.
So, with that in mind, why use MP at all? Wouldn't it a) be a lot simpler and b) a lot faster to simply do (meta code):
while I_should_be_running:
frame = get_latest_frame()
processed = do_work_on_frame()
save_if_needed(processed)
In this case you should likely use multi-threading to implement a way to set/unset I_should_be_running outside of this main loop, but the key point is that the work you're doing is all in a single process.
Honestly, in terms of KISS principle and personally struggled with the (for me at least) always present little wrinkles and complexities with trying to implement MP, based on your problem as you presented it, it might be a lot saner to just run it all as above in a single process...
- If you are using MP, and you only want the most recent frame to process, why use a queue at all?
The code, in the producer, is
- empty current queue
- get new frame
- add the queue
So, why use a queue at all? Instead perhaps just use a single instance variable, say, most_recent_frame that the producer writes to.
You would need to setup locking around this between processes so that the consumer can lock it so that it can copy it to then subsequently do processing. But there are various tools in the MP libraries I believe to do this.
This would avoid a lot of overhead from doing un-needed work (ie processing time): creating unused object instances, pickling those objects in the queue (see https://docs.python.org/3/library/multiprocessing.html#multiprocessing.Queue section around 'Pipes and Queues' - this is slow!) and garbage collection of those un-used objects after they are deleted if not used.
Also, you're using a queue with (in theory) a producer that in constantly adding things, but without a limit. While not a risk in your code (because you're removing all prior entries in the producer), this kind of approach has a potential huge risk of memory overflows if something goes wrong.
- Why use a connection object (ie a Queue) b/w your processes based on
Pipe?
When you use queues in MP it is based on Pipe, which will create a pickled copy of the objects you're using it for. This can be very slow for large and/or complex objects.
Instead if you're concerned about maximum speed, then you could use a ctypes shared memory object (again see https://docs.python.org/3/library/multiprocessing.html#multiprocessing.Queue).
This does need locking (which the MP code provides), but is significantly faster than queue based object pickle/copying for large/complex objects - for which your frame might possibly be.
Considering you're trying to generate frames at multiple 10's of times a second, this pickle/copy overhead would possibly be significant.
CodePudding user response:
I had created a solution to a multiprocessing video problem a while ago that I think can be very applicable to this exact scenario:
Use a multiprocessing.shared_memory backed array as a buffer, and continuously write video frames into it from the process that is reading frames. Then on another process, you can just make a copy of the current frame and go do some processing on it for a while. Any frames written during processing are just over-written by the next until you're ready for another frame.
Take note that the framerate of the video source is different from the framerate of the video display (limited by sleep(1/30) and cv2.waitKey(1000) respectively)
from multiprocessing import Process, Lock
from multiprocessing.shared_memory import SharedMemory
import cv2
from time import sleep
import numpy as np
def process_frames(shm, frame_shape, frame_dtype, frame_lock, exit_flag):
#create numpy array from buffer
frame_buffer = np.ndarray(frame_shape, buffer=shm.buf, dtype=frame_dtype)
try:
while True:
if exit_flag.acquire(False): #try (without waiting) to get the lock, and if successful: exit
break
with frame_lock:
frame = frame_buffer.copy() #don't want the data being updated while processing happens
cv2.imshow('frame', frame)
cv2.waitKey(1000) #this is needed for cv2 to update the gui, and waiting a long time simulates heavy processing
except KeyboardInterrupt: #some systems propogate signals to child processes making exit_flag unnecessary. Others don't
pass
shm.close()
print("child exiting")
def read_and_process_frames():
vid_device = r"D:\Videos\movies\GhostintheShell.mp4" #a great movie
#get the first frame to calculate size
cap = cv2.VideoCapture(vid_device)
success, frame = cap.read()
if not success:
raise Exception("error reading from video")
#create the shared memory for the frame buffer
frame_buffer_shm = SharedMemory(name="frame_buffer", create=True, size=frame.nbytes)
frame_buffer = np.ndarray(frame.shape, buffer=frame_buffer_shm.buf, dtype=frame.dtype)
frame_lock = Lock()
exit_flag = Lock()
exit_flag.acquire() #start in a locked state. When the reader process successfully acquires; that's the exit signal
processing_process = Process(target=process_frames, args=(frame_buffer_shm,
frame.shape,
frame.dtype,
frame_lock,
exit_flag))
processing_process.start()
try: #use keyboardinterrupt to quit
while True:
with frame_lock:
cap.read(frame_buffer) #read data into frame buffer
sleep(1/30) #limit framerate-ish for video file (hitting actual framerate is more complicated than 1 line)
except KeyboardInterrupt:
print("exiting")
exit_flag.release() #signal the child process to exit
processing_process.join() #wait for child to exit
#cleanup
cap.release()
frame_buffer_shm.close()
frame_buffer_shm.unlink()
if __name__ == "__main__":
read_and_process_frames()