I have a Dataframe like this, but much larger:
data = {
"p_id": [1, 1, 1, 2,2,3,3],
"m_id": [11,25,35,11,35,25,35],
"Time": [25,40,10,21,13,15,20]
}
How can i convert it to following list
Jobs = [#(m_id, Time)
[(11,25) , (25,40) , (35,10)] #p_id=1
[(11, 21) , (35,13)]#p_id = 2
[(25,15), (35,20)]#p_id = 3
]
I have tried it with following line, but it does not work properly
df.groupby(‘p_id’)[[‘m_id’,’time’]].apply(list)
Is there a simple way to convert this?
Thank you !
CodePudding user response:
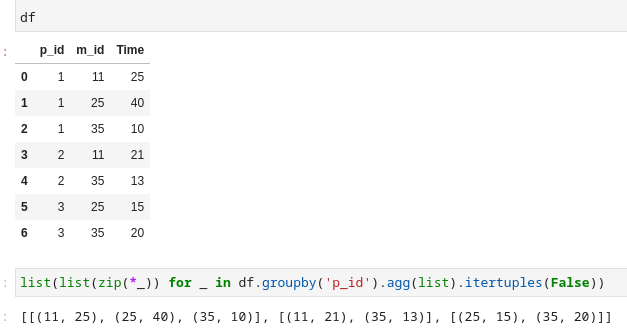
[list(zip(*_)) for _ in df.groupby('p_id').agg(list).itertuples(False)]
- groupby with
p_id - aggregate other columns with list
- iterate them as tuples and drop index(index=False)
- we get
Pandas(m_id=[11, 25, 35], Time=[25, 40, 10]),
Pandas(m_id=[11, 35], Time=[21, 13]),
Pandas(m_id=[25, 35], Time=[15, 20])
but we need to transpose them so we did zip(*_) for it
- zip returns generator so we need to wrap it list
CodePudding user response:
One way is to set p_id as index, then apply tuple on axis=1, then group on level=0, then finally apply list:
>>> out = df.set_index('p_id').apply(tuple, axis=1).groupby(level=0).apply(list)
p_id
1 [(11, 25), (25, 40), (35, 10)]
2 [(11, 21), (35, 13)]
3 [(25, 15), (35, 20)]
After that, you can convert it to Python list if needed:
>>> out.to_list()
[[(11, 25), (25, 40), (35, 10)], [(11, 21), (35, 13)], [(25, 15), (35, 20)]]
Alternate way:
df.groupby('p_id').apply(lambda x: x.iloc[:,1:].apply(tuple, axis=1).tolist()).to_list()
[[(11, 25), (25, 40), (35, 10)], [(11, 21), (35, 13)], [(25, 15), (35, 20)]]